データ型
Zen で使用できるデータ型
ここでは、MicroKernelおよびリレーショナル エンジンを介して Zen によって提供される、データ型およびデータ型マッピングについて説明します。
Zen で使用できるデータ型
次の表は、Zen によってサポートされるトランザクショナル データ型とリレーショナル データ型のマッピングです。Btrieve データ ファイルのデータにアクセスする SQL アプリケーションの開発者に有用です。
表 112 Zen トランザクショナルおよびリレーショナル データ型
トランザクショナル型(サイズ) | リレーショナル型 | メタデータの型コード値 | サイズ(バイト数) | 作成/追加パラメーター1 | データ型に関する注記 |
|---|
AUTOINCREMENT(2) | SMALLIDENTITY | 15 | 2 | | |
AUTOINCREMENT(4) | IDENTITY | 15 | 4 | | |
AUTOINCREMENT(8) | BIGIDENTITY | 15 | 8 | | |
AUTOTIMESTAMP | AUTOTIMESTAMP | 32 | 8 | | 11 |
BFLOAT(4) | BFLOAT4 | 9 | 4 | ヌルでない | 4 |
BFLOAT(8) | BFLOAT8 | 9 | 8 | ヌルでない | 4 |
BLOB | LONGVARBINARY | 21 | N/A2 | ヌルでない | 2、3、6 |
BLOB(2) | NLONGVARCHAR | 21 | N/A2 | ヌルでない
大小文字無視 | 7 |
CLOB | LONGVARCHAR | 21 | N/A2 | ヌルでない
大小文字無視 | 5、6 |
CURRENCY | CURRENCY | 19 | 8 | ヌルでない | |
DATE | DATE | 3 | 4 | ヌルでない | |
なし | DATETIME | 30 | 8 | ヌルでない | 10 |
DECIMAL | DECIMAL | 5 | 1 - 64 | 桁数
小数位
ヌルでない | |
FLOAT(4) | REAL | 2 | 4 | ヌルでない | |
FLOAT(8) | DOUBLE | 2 | 8 | ヌルでない | |
GUID | UNIQUEIDENTIFIER | 27 | 16 | ヌルでない | |
INTEGER(1) | TINYINT | 1 | 1 | ヌルでない | |
INTEGER(2) | SMALLINT | 1 | 2 | ヌルでない | |
INTEGER(4) | INTEGER | 1 | 4 | ヌルでない | |
INTEGER(8) | BIGINT | 1 | 8 | ヌルでない | |
MONEY | DECIMAL | 6 | 1 - 64 | 桁数
小数位
ヌルでない | |
NUMERIC | NUMERIC | 8 | 1 - 37 | 桁数
小数位
ヌルでない | 4 |
NUMERICSA | NUMERICSA | 18 | 1 - 37 | 桁数
小数位
ヌルでない | 4 |
NUMERICSLB | NUMERICSLB | 28 | 1 - 37 | 桁数
小数位
ヌルでない | 4 |
NUMERICSLS | NUMERICSLS | 29 | 1 - 37 | 桁数
小数位
ヌルでない | 4 |
NUMERICSTB | NUMERICSTB | 31 | 1 - 37 | 桁数
小数位
ヌルでない | 4 |
NUMERICSTS | NUMERICSTS | 17 | 1 - 37 | 桁数
小数位
ヌルでない | 4 |
STRING | BINARY | 0 | 1 - 8,000 | サイズ
ヌルでない
大小文字無視 | 2、3 |
STRING | CHAR | 0 | 1 - 8,000 | サイズ
ヌルでない
大小文字無視 | 1 |
TIME | TIME | 4 | 4 | ヌルでない | |
TIMESTAMP | TIMESTAMP | 20 | 8 | ヌルでない | |
TIMESTAMP2 | TIMESTAMP2 | 34 | 8 | ヌルでない | 11 |
UNSIGNED(1) BINARY | UTINYINT | 14 | 1 | ヌルでない | |
UNSIGNED(2) BINARY | USMALLINT | 14 | 2 | ヌルでない | |
UNSIGNED(4) BINARY | UINTEGER | 14 | 4 | ヌルでない | |
UNSIGNED(8) BINARY | UBIGINT | 14 | 8 | ヌルでない | |
WSTRING | NCHAR | 25 | 2 - 8,000 | サイズ 1 - 4,000
ヌルでない
大小文字無視 | 12、13 |
WZSTRING | NVARCHAR | 26 | 2 - 8,000 | サイズ 1 - 4,000
ヌルでない
大小文字無視 | 12、14 |
ZSTRING | VARCHAR | 11 | 1 - 8,000 | サイズ
ヌルでない
大小文字無視 | 5 |
なし | BIT | 16 | 1 ビット | | 6、8 |
LOGICAL(1) | BIT | 7 | 1 ビット | | 9 |
LOGICAL(2) | SMALLINT | 1 | 2 | ヌルでない | |
1 必須パラメーターは「桁数」と「サイズ」です。オプション パラメーターは「大小文字無視」、「ヌルでない」、および「小数位」です。 2 "N/A" は "not applicable"(適用外)を表します。 データ型に関する注記 1. 空白で埋められます 2. FIELD.DDF で、バイナリの使用を SQL に知らせるフラグ セット。『 Distributed Tuning Interface Guide』の COLUMNMAP フラグおよび『 Distributed Tuning Objects Guide』の 列フラグを参照してください。 3. バイナリ ゼロで埋められます 4. 変数としても、またストアド プロシージャ内でも使用できません 5. 埋め込みなし 6. インデックスを作成できません 7. FIELD.DDF で、NLONGVARCHAR の使用を SQL に知らせるフラグ セット。『 Distributed Tuning Interface Guide』の COLUMNMAP フラグおよび『 Distributed Tuning Objects Guide』の 列フラグを参照してください。 8. TRUEBITCREATE は on(デフォルト)に設定する必要があります。 9. TRUEBITCREATE は off に設定する必要があります。 10. 型コード 30 は MicroKernel エンジンの型コードではありません。リレーショナル エンジン メタデータ内における DATETIME の識別子です。 11. UBIGINT と同じようにソートされます。 12. Unicode 型の場合、列のサイズは 2 バイトの UCS-2 単位の数を表します。 13. Unicode の空白(2 バイト)で埋められます。 14. Unicode の NUL 文字(2 バイト、バイナリ ゼロ)で埋められます。 |
データ型の範囲
次の表は、Zen データ型で有効な値の範囲と、必要に応じてそれらに増分される値を示したものです。
表 113 Zen データ型の範囲
リレーショナル データ型 | 有効値の範囲 |
|---|
AUTOTIMESTAMP | 1970-01-01 00:00:00.000000000 ~ 2554-07-21 23:34:33.709551615 セロで初期化すると、挿入または次回の更新で現在の日時が使用されます。 |
BFLOAT4 | -1.70141172e+38 ~ +1.70141173e+38 BFLOAT4 をインクリメントまたはデクリメントできる最小値は 2.938736e-39 です。 |
BFLOAT8 | -1.70141173e+38 ~ +1.70141173e+38 BFLOAT8 をインクリメントまたはデクリメントできる最小値は 2.93873588e-39 です。 |
BIGIDENTITY | -9223372036854775808 ~ +9223372036854775807 |
BIGINT | -9223372036854775808 ~ +9223372036854775807 |
BINARY | 範囲は適用されません |
BIT | 範囲は適用されません |
CHAR | 範囲は適用されません |
CURRENCY | -922337203685477.5808 ~ +922337203685477.5807 |
DATE | 01-01-0001 ~ 12-31-9999 メモ:00-00-0000 は有効な値ではありません。DATE 型の値に 00-00-0000 データが入っているレガシー データがある場合は、クエリに "is null" を使用することでそれを照会できます。 |
DATETIME | 1753-01-01 00:00:00.000 ~ 9999-12-31 23:59:59.999。1 ミリ秒の精度 |
DECIMAL | 長さと小数点以下の桁数によって異なります |
DOUBLE | -1.7976931348623157e+308 ~ +1.7976931348623157e+308 DOUBLE をインクリメントまたはデクリメントする最小値は 2.2250738585072014e-308 です。 |
FLOAT | -1.7976931348623157E+308 ~ +1.7976931348623157E+308 FLOAT をインクリメントまたはデクリメントできる最小値は 2.2250738585072014e-308 です。 |
IDENTITY | -2147483648 ~ +2147483647 |
INTEGER | -2147483648 ~ +2147483647 |
LOGICAL | 範囲は適用されません |
LONGVARBINARY | 範囲は適用されません |
LONGVARCHAR | 範囲は適用されません |
MONEY | -99999999999999999.99 ~ +99999999999999999.99 |
NCHAR | 範囲は適用されません |
NLONGVARCHAR | 範囲は適用されません |
NUMERIC | 長さと小数点以下の桁数に基づきます。 Decimal データ型の精度と小数位を参照してください。 |
NUMERICSA | 長さと小数点以下の桁数に基づきます。 Decimal データ型の精度と小数位を参照してください。 |
NUMERICSLB | 長さと小数点以下の桁数に基づきます。 Decimal データ型の精度と小数位を参照してください。 |
NUMERICSLS | 長さと小数点以下の桁数に基づきます。 Decimal データ型の精度と小数位を参照してください。 |
NUMERICSTB | 長さと小数点以下の桁数に基づきます。 Decimal データ型の精度と小数位を参照してください。 |
NUMERICSTS | 長さと小数点以下の桁数に基づきます。 Decimal データ型の精度と小数位を参照してください。 |
NVARCHAR | 範囲は適用されません |
REAL | -3.4028234E+38 ~ +3.4028234e+38 REAL 値をインクリメントまたはデクリメントできる最小値は 1.4E-45 です。 |
SMALLIDENTITY | -32768 ~ +32767 |
SMALLINT | -32768 ~ +32767 |
TIME | 00:00:00 ~ 23:59:59 |
TIMESTAMP | 0001-01-01 00:00:00.0000000 ~ 9999-12-31 23:59:59.9999999 UTC |
TIMESTAMP2 | 1970-01-01 00:00:00.000000000 ~ 2554-07-21 23:34:33.709551615 UTC |
TINYINT | -128 ~ +127 |
UBIGINT | 0 ~ 18446744073709551615 |
UINTEGER | 0 ~ 4294967295 |
UNIQUEIDENTIFIER | 範囲は適用されません |
USMALLINT | 0 ~ 65535 |
UTINYINT | 0 ~ 255 |
VARCHAR | 範囲は適用されません |
演算子の優先順位
式には複数の演算子が含まれることがあり、それらは優先順位に従って実行されます。Zen で使用される順序は次のとおりで、レベル 1 が最高、レベル 9 が最低です。高レベルの演算子は低レベルの演算子より先に評価されます。
1 +(正)、-(負、否定)、~(ビット演算 NOT)
2 *(乗算)、/(除算)、%(剰余)
3 +(加算)、(+ 連結)、-(減算)、&(ビット演算 AND)
4 =、>、<、>=、<=、<>、!=(これらの比較演算子はそれぞれ、等しい、より大きい、より小さい、以上、以下、等しくない、を表します)
5 ^(ビット演算 排他的 OR)、|(ビット演算 OR)
6 NOT
7 AND
8 ALL、ANY、BETWEEN、IN、LIKE、OR、SOME
9 =(代入)
式内にある同じ優先レベルの演算子は、左から右へ評価されます。たとえば、SET :Counter = 12 / 4 * 7 では、除算は乗算より先に評価され、結果として 21 が返されます。
かっこ
かっこを使用すると、演算子の優先順位より優先させることができます。最初にかっこ内のものがすべて評価され、1 つの値がもたらされます。その後、この値がかっこの外にある演算子で使用されます。たとえば、次のステートメントの場合、除算演算子は通常は加算演算子より先に評価されます。結果は 12 になります(つまり、8 + 4)。しかし、加算はかっこで囲まれているため最初に実行されるので、プロシージャは結果の 4 を返します。
SET :Counter = 32 / (4 + 4)
式にネストされたかっこがある場合は、一番深くネストされている式が最初に評価され、次に深くネストされている式の順に評価されます。たとえば、次のステートメントでは、加算が最初に実行され、次に乗算、減算、最後に除算が実行されます。結果は値 5 になります。
SET :Counter = 100 / (40 - (2 * (5 + 5)));
データ型の優先順位
データ型の優先順位は、異なる型の 2 つの式が演算子によって結合されているときに、その結果の型を決定します。優先順位の低いデータ型は優先順位の高いデータ型に変換されます。
メモ:互換性のないデータ型で演算を行う、たとえば INTEGER を CHAR に加算すると、エラーが返されます。
数値データ型
リレーショナルの数値データ型では次の優先順位を使用します。
1 DOUBLE、FLOAT、BFLOAT8(最高)
2 REAL、BFLOAT4
3 DECIMAL、NUMERIC、NUMERICSA、NUMERICSTS
4 NUMERICSLS、NUMERICSTB、NUMERICSLB
5 CURRENCY、MONEY
6 BIGINT、UBIGINT、BIGIDENTITY
7 INTEGER、UINTEGER、IDENTITY
8 SMALLINT、USMALLINT、SMALLIDENTITY
9 TINYINT、UTINYINT
10 BIT(最低)
文字データ型
リレーショナルの文字データ型では次の優先順位を使用します。
1 NLONGVARCHAR
2 NCHAR、NVARCHAR
3 LONGVARCHAR
4 CHAR、VARCHAR
NCHAR または NVARCHAR と NLONGVARCHAR を連結させた場合、結果は NLONGVARCHAR になります。
NCHAR と LONGVARCHAR を連結させた場合、結果は NLONGVARCHAR になります。
CHAR または VARCHAR と LONGVARCHAR を連結させた場合、結果は LONGVARCHAR になります。
CHAR と VARCHAR を連結させた場合、結果の型はその連結で最初にくるデータ型になります。つまり左から右に移動します。たとえば、c1 が CHAR で c2 が VARCHAR の場合、(c1 + c2)の結果は CHAR になり、(c2 + c1)の結果は VARCHAR になります。
優先順位のないデータ型
BINARY、LONGVARBINARY、および UNIQUEIDENTIFIER データ型の優先順位はありません。これらのデータ型を組み合わせる演算は許可されていません。
日付と時刻のデータ型は、他のどの日付または時刻のデータ型とも組み合わせることができません。
Decimal データ型の精度と小数位
精度は、数値内の数字の数(桁数)です。小数位は、数値内の小数点より右側の数字の数です。たとえば、909.777 という数では精度が 6 で小数位が 3 となります。
NUMERIC、NUMERICSA、および DECIMAL データ型の最大精度は 64 です。NUMERICSTS および NUMERICSLS では、プラスまたはマイナス符号のために 1 バイトが予約されているため、最大精度は 63 です。
DECIMAL を除くすべての数値データ型で、精度と小数位は固定です。同じデータ型の 2 つの式で算術演算を行った場合、結果は同じデータ型となり、そのデータ型の精度と小数位を持ちます。データ型が異なる式で演算を行った場合は、優先順位のルールによって結果のデータ型が決定されます。結果の精度と小数位は、そのデータ型に定義されている桁数になります。
次の条件における演算の場合、結果は DECIMAL になります。
•両方の式が DECIMAL。
•一方の式が DECIMAL で、他方の式が DECIMAL よりも優先順位の低いデータ型。
表
114 は、演算結果のデータ型が DECIMAL になる場合に精度と小数位を導き出す方法の定義を示しています。
exp は「式」を表し、
s は「小数位」、
p は「精度」を表します。
表 114 DECIMAL 演算の精度と小数位の計算方法
演算 | 精度 | 小数位 |
|---|
Addition (exp1 + exp2) | max(s1, s2) + max(p1 - s1, p2 - s2) +1 | max(s1, s2) |
Subtraction (exp1 - exp2) | max(s1, s2) + max(p1 - s1, p2 - s2) +1 | max(s1, s2) |
Multiplication (exp1 * exp2) | p1 + p2 + 1 | s1 + s2 |
Division (exp1 / exp2) | p1 - s1 + s2 + max(6, s1 + p2 +1) | max(6, s1 + p2 +1) |
UNION (exp1 UNION exp2) | max(s1, s2) + max(p1 - s1, p2 - s2) +1 | max(s1, s2) |
たとえば、DECIMAL(8,2)および DECIMAL(7,4)と定義されている 2 つのフィールドを加算または減算した場合、結果フィールドは DECIMAL(11,4)になります。
タイムスタンプ データ型の小数位と返される関数値
タイムスタンプ データ型では、小数位はタイムスタンプ内の小数の秒部分の小数点より右側の桁数です。たとえば、2019-12-31 23:59:59.782 では小数位は 3 桁、つまりミリ秒となります。
Zen 14.10 から、TIMESTAMP データ型および TIMESTAMP2 データ型の小数位を選択できるようになりました。たとえば、次の SQL スクリプトは 4 つの列を持つテーブルを作成します。各列は TIMESTAMP または TIMESTAMP2 とし、最初の 2 列はデフォルトの小数位を持ち、次の 2 列は小数位を小数点以下 1 桁に設定しています。
create table times
(ts timestamp default sysdatetime(),
ts2 timestamp2 default sysdatetime(),
ts_1 timestamp(1) default sysdatetime()
ts2_1 timestamp2(1) default sysdatetime());
insert into times default values;
select * from times;
SELECT ステートメントは次の行を返します。
ts ts2 ts-1 ts2-1
======================= ============================= ===================== =====================
2019/12/10 10:25:39.555 2019/12/10 10:25:39.555080200 2019/12/10 10:25:39.5 2019/12/10 10:25:39.5
小数位を短くした場合、小数の秒は丸められないことに留意してください。
次の表は、小数位を持つ日付およびタイムスタンプをサポートする Zen データ型の一覧を示します。
データ型 | デフォルトの小数位を含む形式 | 小数位 |
|---|
AUTOTIMESTAMP | yyyy-mm-dd hh:mm:ss.nnnnnnnnn(ナノ秒) | 9 |
DATETIME | yyyy-mm-dd hh:mm:ss.nnn(ミリ秒) | 3 |
TIMESTAMP | yyyy-mm-dd hh:mm:ss.nnn(ミリ秒) | 3 |
TIMESTAMP(n) | yyyy-mm-dd hh:mm:ss.nnnnnnn(なし~セプタ秒) | 0-7 |
TIMESTAMP2 | yyyy-mm-dd hh:mm:ss.nnnnnnnnn(ナノ秒) | 9 |
TIMESTAMP2(n) | yyyy-mm-dd hh:mm:ss.nnnnnnnnn(なし~ナノ秒) | 0-9 |
次の表は、小数位を持つ日付値およびタイムスタンプ値を返す Zen スカラー関数の一覧を示します。
関数 | 形式 | 小数位 |
|---|
CURRENT_TIMESTAMP() | yyyy-mm-dd hh:mm:ss.nnn(ミリ秒) | 3 |
NOW() | yyyy-mm-dd hh:mm:ss.nnn(ミリ秒) | 3 |
SYSDATETIME() | yyyy-mm-dd hh:mm:ss.nnnnnnnnn(ナノ秒) | 9 |
SYSUTCDATETIME() | yyyy-mm-dd hh:mm:ss.nnnnnnnnn(ナノ秒) | 9 |
関数から返されるタイムスタンプの小数位が、その値が書き込まれる列のデータ型の小数位より小さい場合、末尾の小数点以下桁数はゼロで埋められます。たとえば、CURRENT_TIMESTAMP() の値を TIMESTAMP2 列に入れるとした場合は、値 2019/12/10 14:23:46 292000000 が返されます。
切り捨て
アプリケーションが異なる SQL DBMS 製品に対して実行される場合は、切り捨てに関する以下の問題が発生する可能性があります。
特定の状況で、一部の SQL DBMS 製品では切り捨てのためにデータを挿入できないのに、Zen ではその同じデータを挿入できることがあります。さらに、Zen の SQL_SUCCESS_WITH_INFO のレポートと切り捨てられる情報は、メッセージが報告されるタイミングに基づく特定のシナリオにおいて、一部の SQL DMBS 製品と異なります。
数値文字列データおよび数値データは、Zen では常に切り捨てられるのに対し、SQL DBMS 製品では丸められます。たとえば、数値文字列または数値の 123.457 があり、これを 6 バイトの文字列の列または小数部 2 桁の数値列に挿入する場合、Zen は常に 123.45 を挿入します。これに対して、ほかの DBMS 製品は 123.46 という値を挿入することがあります。
データ型に関する注意事項
このトピックでは、使用可能なデータ型に関するさまざまな動作およびキー情報について説明します。
CHAR、NCHAR、VARCHAR、NVARCHAR、LONGVARCHAR、および NLONGVARCHAR
•CHAR および NCHAR 列には、末尾の空白が埋め込まれます。比較演算(LIKE および =)では、このような空白は演算の対象になりません。ただし、LIKE の場合、クエリに空白が明示的に入力されているとき('abc %' など)は、ワイルドカードの前の空白は演算の対象になります。この例の場合、'abc<空白><任意の文字>' を検索します。
•CHAR 型は、データベース コード ページを使用して、つまり、1 文字につき 1 バイト以上を使用して文字を格納します。NCHAR 型は、UCS-2 の 2 バイト値として文字を格納します。
•VARCHAR、NVARCHAR、LONGVARCHAR、および NLONGVARCHAR 値は末尾の空白は埋め込まれません。意味のあるデータはヌル文字で終わります。
•VARCHAR および NVARCHAR の比較演算子では、末尾の空白は意味を持ちます。たとえば c1 = 'Test ' とした場合、c1 が VARCHAR 型であるとき、値 'Test' を含む列は検出されません。
BINARY および LONGVARBINARY
•BINARY 列には、末尾のゼロが埋め込まれます。
•LONGVARBINARY 列には、末尾のゼロは埋め込まれません。
•データベース エンジンは、LONGVARBINARY 列の比較はできません。データベース エンジンは、固定長の BINARY データの比較はできます。
Zen では、1 つのテーブルで複数の LONGVARCHAR 列および LONGVARBINARY 列がサポートされます。データは、オフセットに応じてレコードの可変長部分に格納されます。データの可変長部分は、データの操作方法に応じて、データの列順とは異なるものにすることができます。次の例で考えてみましょう。
CREATE TABLE BlobDataTest
(
Nbr UINT, // 固定レコード (型 14)
Clob1 LONGVARCHAR, // 固定レコード (型 21)
Clob2 LONGVARCHAR, // 固定レコード (型 21)
Blob1 LONGVARBINARY, // 固定レコード (型 21)
)
ディスク上では、物理レコードは通常次のように見えます。
[固定データ (Nbr, Clob1header, Clob2header, Blob1header)][ClobData1][ClobData2][BlobData1]
列 Nbr を LONGVARCHAR 列に変更します。
ALTER TABLE BlobDataTest ALTER Nbr LONGVARCHAR
これで、物理レコードはディスク上で次のように見えるようになりました。
[固定データ (Nbrheader, Clob1header, Clob2header, Blob1header)][ClobData1][ClobData2][BlobData1]
[NbrClobData]
見たとおり、データの可変長部分は既存のデータの列順には入りません。
しかし、新しく挿入したレコードについては、データの可変長部分は既存のデータの列順に入ります。これは、すべての列にデータが割り当てられている(列がヌルでない)ことを前提としています。
[固定データ (Nbrheader, Clob1header, Clob2header, Blob1header)][NbrClobData][ClobData1][ClobData2]
[BlobData1]
LONGVARCHAR、NLONGVARCHAR、および LONGVARBINARY の制約
LONGVARCHAR および LONGVARBINARY データ型には次の制約が適用されます。
•LIKE 述部は、列データの最初の 65500 バイトに適用されます。
•その他の述部はすべて、列データの最初の 256 バイトに適用されます。
•GROUP BY、DISTINCT、および ORDER BY を伴った SELECT ステートメントはすべてのデータを返しますが、列データの最初の 256 バイトにのみ指示を行います。
•LONGVARCHAR および LONGVARBINARY 型の列には最大 2 GB までデータを挿入できますが、INSERT ステートメントでリテラル値を使用すると、挿入可能なバイト数は 15000 に減ります。ただし、パラメーター化された INSERT を使用することによって、15000 バイト以上挿入することは可能です。
•Zen による 1 回の呼び出しで、LONGVARCHAR、NLONGVARCHAR、または LONGVARBINARY 列に対して返される最大のバイト数は、アプリケーションが使用するアクセス方法によって異なります。ほとんどの場合、この制限は 65500 バイトです。詳細については、特定の開発環境用のドキュメントを参照してください。
DATETIME
DATETIME データ型は日付と時刻の値を表します。この型は、内部的に 2 つの 4 バイト整数として格納されます。最初の 4 バイトは基準日である 1900 年 1 月 1 日より前または後の日数を格納します。あとの 4 バイトは、深夜 0 時からのミリ秒数で表すその日の時刻を格納します。
DATETIME データ型はインデック付けすることができます。DATETIME の精度は 1 ミリ秒です。
DATETIME はリレーショナル データ型のみです。対応する Btrieve データ型はありません。
DATETIME の書式
DATETIME の書式は YYYY-MM-DD HH:MM:SS.mmm のみです。ミリ秒部分を切り捨てる必要がある場合は、CONVERT 関数にそれを行うためのパラメーターがあります。次の表に、DATETIME のデータ コンポーネントとそれらの値の範囲を示します。
コンポーネント | 有効な値 |
|---|
Year(YYYY) | 1753 ~ 9999 |
Month(MM) | 01 ~ 12 |
Day(DD) | 01 ~ 31 |
Hour(HH) | 00 ~ 23 |
Minute(MM) | 00 ~ 59 |
Second(SS) | 00 ~ 59 |
Millisecond(mmm) | 000 ~ 999 |
日付と時刻のデータ型の互換性
日付や時刻のデータ型を含む加算または減算を実行する必要がある場合は、スカラー関数の TIMESTAMPADD()、DATEADD()、TIMESTAMPDIFF()、および DATEDIFF() を使用することをお勧めします。式に新しい AUTOTIMESTAMP データ型および TIMESTAMP2 データ型が含まれている場合には、これらの関数の使用が必要になります。他のデータ型は、場合によっては演算子と共に式で直接使用できます。たとえば、次のステートメントは有効です。
SELECT "Start_Date" + 5 FROM "Class"
SELECT "Finish_Time" – "Start_Time" FROM "Class"
SELECT current_timestamp() – "Log" FROM "Billing"
クエリによっては、"互換性のない型" または "式にエラーがあります" というメッセージを返す可能性があります。たとえば、互換性のない値を加算または減算しようとするクエリや、結果が有効にならないクエリがこれに当たります。たとえば、次のステートメントはそのようなエラーを返します。
SELECT "Start_Date" + 5.0 FROM "Class"
SELECT "Start_Time" + "Finish_Time" FROM "Class"
SELECT current_timestamp() + "Log" FROM "Billing"
CONVERT 関数および CAST 関数は、次の表に示すように DATE、DATETIME、TIME、および TIMESTAMP と使用できます。
表 115 許可される CONVERT 操作
変換元 | 許可される結果のデータ型(変換先) |
|---|
AUTOTIMESTAMP | SQL_CHAR、SQL_DATE、SQL_TIME、SQL_TIMESTAMP、SQL_VARCHAR |
DATE | SQL_CHAR、SQL_DATE、SQL_TIMESTAMP、SQL_VARCHAR |
DATETIME | GUID、BINARY、および LONGVARBINARY 以外の、サポートされる CONVERT データ型。CONVERT の type パラメーターには、プレフィックス "SQL_" が必要です。 CONVERT(exp, type[, style ]) を参照してください。 |
TIME | SQL_CHAR、SQL_TIME、SQL_TIMESTAMP、SQL_VARCHAR |
TIMESTAMP | SQL_CHAR、SQL_DATE、SQL_TIME、SQL_TIMESTAMP、SQL_VARCHAR |
TIMESTAMP2 | SQL_CHAR、SQL_DATE、SQL_TIME、SQL_TIMESTAMP、SQL_VARCHAR |
VARCHAR | SQL_CHAR、SQL_DATE、SQL_TIME、SQL_TIMESTAMP、SQL_VARCHAR |
メモ:CONVERT 関数には DATETIME のミリ秒部分を切り捨てることができるオプション パラメーターがあります。
変換関数の Convert 関数を参照してください。
表 116 許可される CAST 操作
キャスト元 | 許可される結果のデータ型(変換先) |
|---|
AUTOTIMESTAMP | DATE、DATETIME、TIME、TIMESTAMP、TIMESTAMP2、VARCHAR |
DATE | DATE、DATETIME、TIMESTAMP、VARCHAR |
DATETIME | 任意のリレーショナル データ型 |
TIME | TIME、DATETIME、TIMESTAMP、TIMESTAMP2、VARCHAR |
TIMESTAMP | DATE、DATETIME、TIME、TIMESTAMP、TIMESTAMP2、VARCHAR |
TIMESTAMP2 | DATE、DATETIME、TIME、TIMESTAMP、TIMESTAMP2、VARCHAR |
VARCHAR | DATE、DATETIME、TIME、TIMESTAMP、TIMESTAMP2 |
UNIQUEIDENTIFIER
UNIQUEIDENTIFIER データ型は GUID(Globally Unique Identifier:グローバル一意識別子)として知られている 16 バイトのバイナリ値です。GUID は、行がほかの行と重複しない場合に有用です。
UNIQUEIDENTIFIER は、9.5 以降のファイル形式を必要とします。
UNIQUEIDENTIFIER の列またはローカル変数は、以下の方法で初期化できます。
•NEWID() スカラー関数を使用します。
NEWID( ) を参照してください。
•'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx' 形式の引用符で囲んだ文字列を指定します。x は 0-9 または A-F の範囲の 16 進数です。たとえば、'1129619D-772C-AAAB-B221-00FF00FF0099' は有効な UNIQUEIDENTIFIER 値です。
引用符で囲んだ文字列を指定する場合、32 桁全部を指定する必要があります。データベース エンジンは部分文字列の埋め込み処理を行いません。
以下の比較演算子のみが UNIQUEIDENTIFIER に使用できます。
演算子 | 意味 |
|---|
= | 等しい |
<> または != | 等しくない |
< | より小さい |
> | より大きい |
<= | 小さいかまたは等しい |
>= | 大きいかまたは等しい |
IS NULL | 値はヌルです |
IS NOT NULL | 値はヌルではありません |
2 つの値のビット パターンの比較によっては並べ替えは行われません。
変数を宣言する
SET ステートメントを使用して UNIQUEIDENTIFIER データ型の変数を宣言することができます。
DECLARE :Cust_ID UNIQUEIDENTIFIER DEFAULT NEWID()
DECLARE :ISO_ID uniqueidentifier
SET :ISO_ID = '1129619D-772C-AAAB-B221-00FF00FF0099'
UNIQUEIDENTIFIER を別のデータ型に変換する
UNIQUEIDENTIFER は CAST または CONVERT スカラー関数使用して以下のデータ型のいずれかに変換できます。
•CHAR
•LONGVARCHAR
•VARCHAR
無限の表現
Zen で無限を表すには、次の表のように、4 バイト(C 言語の float 型)または 8 バイト(C 言語の double 型)の形式で、16 進数または文字として表現できます。
表 117 無限の表現
値 | Float 16 進数 | Float 文字 | Double 16 進数 | Double 文字 |
|---|
正の最大数 | | | 0x7FEFFFFFFFFFFFFF | |
負の最大数 | | | 0xFFEFFFFFFFFFFFFF | |
正の無限数 | 0x7F800000 | 1E999 | 0x7FF0000000000000 | 1E999 |
負の無限数 | 0xFF800000 | -1E999 | 0xFFF0000000000000 | -1E999 |
旧データ型
いくつかの古い(レガシー)データ型は、現行リリースの Zen ではサポートされていません。次の表は、旧データ型に代わって使用する新データ型を示します。
表 118 旧データ型に代わって使用される新データ型
旧データ型 | 型コード | 代替データ型 | 型コード |
|---|
LOGICAL(1) | 7 | BIT | 16 |
LOGICAL(2) | 7 | SMALLINT | 14 |
LSTRING | 10 | VARCHAR | 11 |
LVAR | 13 | LONGVARCHAR | 21 |
NOTE | 12 | LONGVARCHAR | 21 |
上記のデータ型を使用している既存のデータベースはサポートされており、正しく機能します。新しいデータベースでは旧形式のデータ型を持つテーブルを作成することはできません。ただし、IN DICTIONARY 句を使用して、新しいデータベースの DDF に旧データ型を持つテーブルを追加することはできます。
CREATE TABLE を参照してください。
Btrieve キーのデータ型
このトピックでは、インデックスを作成できる Btrieve データ型(キー タイプ)について説明します。MicroKernel は内部的に、文字列キーを 1 バイトずつ左から右へ比較します。デフォルトで、MicroKernel は ASCII 値に基づいて文字列キーをソートします。しかし、文字列キーは、大文字小文字を無視したり、オルタネート コレーティング シーケンス(ACS)を使用するように定義することもできます。
MicroKernel は、符号なしバイナリ キーを一度に 1 WORD ずつ比較します。Intel 8086 プロセッサ ファミリは Integer の上位バイトと下位バイトを反転させるため、MicroKernel はこれらのキーを右から左へ比較します。
特定のデータ型が複数のサイズで使用できる(たとえば、4 バイトと 8 バイトの FLOAT 値が使用できる)場合は、(新しいキーの作成に使用される)キー長パラメーターにより、そのキーのすべての値に適用されるサイズが定義されます。許可されていないキーの長さを使ってキーを定義しようとすると、ステータス 29(キー長が不正)になります。
次の表は、キー タイプとそれに関連付けられたコードの一覧を示します。表に続いて、各キー タイプの内部記憶形式について説明します。
表 119 Btrieve キーのデータ型と型コード
データ型 | 型コード | | データ型 | 型コード |
|---|
| 15 | | | 8 |
| 32 | | | 18 |
| 9 | | | 28 |
| 0 | | | 29 |
| 19 | | | 31 |
| 3 | | | 17 |
| 5 | | | 4 |
| 2 | | | 20 |
| 27 | | | 34 |
| 1 | | | 14 |
| 7 | | | 25 |
| 10 | | | 26 |
| 6 | | | 11 |
AUTOINCREMENT
AUTOINCREMENT キー タイプは、2 バイト、4 バイト、または 8 バイト長の符号付き Intel 整数です。autoincrement キーは、内部的に Intel バイナリ整数形式で格納され、WORD 内で上位バイトと下位バイトが反転されています。MicroKernel は autoincrement キーをその絶対値を基に、右から左へと一度に 1 WORD ずつ別のレコードに保存されている値と比較してソートします。autoincrement キーを使用すると、ファイルにレコードを挿入するとき、既存の最大の値より 1 大きい値を自動的に割り当てることができます。値は絶対値を基にソートされるため、データ型が符号付きと考えた場合、可能性のあるレコード数は期待するレコード数のおおよそ半分になります。
ファイルから削除された値は、自動的には再使用されません。挿入または更新でゼロ(0)値を入力したら次に来る値を割り当てるようにデータベース エンジンに指示している場合、データベースは単純に最も大きい値を調べ、その値に 1 を足した結果を挿入します。
すべてのレコードまたは一部のレコードで 1 つのフィールドの値を 0 に初期化し、後から AUTOINCREMENT タイプのインデックスを追加できます。この機能により、必要になるまで実際にインデックスを作成しなくても autoincrement キーの準備をすることができます。
インデックスを追加すると、MicroKernel は各フィールドの 0 値を適切に変更します。値の番号付けは、そのフィールドで現在定義されている最大値に 1 を足した値から始まります。フィールドに 0 以外の値が存在する場合、MicroKernel はそれらを変更しません。ただし、0 以外の重複する値がフィールドに存在する場合は、MicroKernel はエラー ステータス コードを返します。
MicroKernel は、autoincrement キーを含んでいる各オープン ファイルに関連付けられる自動インクリメント値の、以前に使用した最大値を保持します。この値は、autoincrement フィールドに ASCII ゼロを含むレコードについて INSERT オペレーションが発生した場合にのみ、確立されて増加します。キー ページの並行性を利用して同時変更が行えるように、値はすべてのクライアントから使用されます。
ファイルの次の autoincrement 値は、前の autoincrement 値を使った INSERT が発生するたびに増加されます。これは、INSERT がトランザクション内にあるかどうか、また変更がコミットされるかどうかに関係なく起こります。
ただし、以下の項目がすべて真の場合には、INSERT 中にこの値を小さくすることができます。
•キー内にある最大の autoincrement 値が、ファイルに対する次の autoincrement 値よりも小さい。
•ほかのどのクライアントも、最大の autoincrement 値を含んでいるページに影響を与えるトランザクションを保留にしていない。
•最大の autoincrement 値を含むキー ページが、INSERT を行っているクライアントによって保留にされていない。
つまり、1 トランザクション内の最初の INSERT のみが、次回使用可能な autoincrement 値を小さくすることができます。その後、次回使用可能な autoincrement 値は増加し続けます。
例を示して、autoincrement 値を小さくできる方法をわかりやすくしましょう。レコード 1、2、3 および 4 を含む自動インクリメント ファイルがあるとします。次回使用可能な autoincrement 値は 5 です。
クライアント1 がトランザクションを開始し、新しいレコードを 2 件挿入すると、次回使用可能な autoincrement 値は 7 に増えます(クライアント1 は値 5 と 6 を取得します)。クライアント2 がトランザクションを開始し、また新しいレコードを 2 件挿入します。これにより、次回使用可能な autoincrement 値は 9 に増えます(クライアント2 は値 7 と 8 を取得します)。
クライアント1 がレコード 4、5、6 を削除します。次回使用可能な autoincrement 値は INSERT でしか調整されないので、同じ値のままです。次に、クライアント1 がコミットを行います。コミットされたバージョンのファイルには、現在レコード 1、2 および 3 が含まれています。
クライアント2 の場合、ファイルにはレコード 1、2、3、7 および 8 が含まれます(7 と 8 はまだコミットされていません)。次にクライアント2 がもう 1 件レコードを挿入すると、レコード 9 になり、次回使用可能な autoincrement 値は 10 に増えます。クライアント2 がレコード 3、7、8、9 を削除します。クライアント2 では、現在ファイルにはコミット済みのレコード 1 と 2 だけが含まれています。
次にクライアント2 がもう 1 件レコードを挿入すると、レコード 10 になります。次回使用可能な autoincrement 値は 11 に増えます。この値は、変更を含んでいるページに保留状態のほかの変更があるため、3 に減らされません。
次に、クライアント2 がトランザクションを中止します。コミットされたバージョンのファイルには、現在レコード 1、2 および 3 が含まれていますが、次回使用可能な autoincrement 値は 11 のままです。
どちらかのクライアントが、トランザクションの内外を問わずもう 1 件レコードを挿入すると、次回使用可能な autoincrement 値は 4 に減少されます。これは、値を小さくするのに必要な条件がすべて真であるために起こります。
自動インクリメントした値が範囲外になる場合は、ステータス コード 5 が返されます。データベース エンジンは、値の「折り返し」を試みることも、再度ゼロから始めることもしません。ただし、以前に挿入した値が削除されており、自動インクリメントのシーケンス中で欠番になっている箇所がわかる場合は、未使用値を直接挿入することができます。
制限
AUTOINCREMENT 型のキーには次の制限が適用されます。
•重複のないキーとして定義する必要があります。
•キーをセグメント キーにすることはできません。ただし、autoincrement キーが個別の単一のキーとして最初に定義されており、autoincrement キー番号がセグメント キーのキー番号よりも小さい場合に限り、autoincrement キーを別のキーの整数セグメントとして含めることができます。
•ほかのキーとオーバーラップすることはできません。
•キーはすべて昇順でなければなりません。
ファイルにレコードを挿入すると、MicroKernel は autoincrement キー値を次のように扱います。
•autoincrement キーにバイナリ 0 の値を指定した場合、MicroKernel は以下の基準に沿ってキーに値を割り当てます。
•ファイルに最初のレコードを挿入する場合、MicroKernel は autoincrement キーに値 1 を割り当てます。
•ファイル内に既にレコードが存在する場合、MicroKernel は autoincrement キーに、ファイル内の既存の最も大きい絶対値より 1 大きい値を割り当てます。
•autoincrement キーに 0 以外の正の値を指定した場合、MicroKernel はファイルにレコードを挿入し、指定した値をキー値として使用します。その値を含むレコードがファイルに既に存在する場合、MicroKernel はエラー ステータス コードを返し、そのレコードを挿入しません。
AUTOTIMESTAMP
AUTOTIMESTAMP キー タイプは 8 バイトの符号なし整数で、Unix エポックに基づいてナノ秒単位で時間を追跡します。値 0 は、新しいレコードが挿入されたとき、または既存のレコードが初めて更新されたときに、この値を自動的に現在の時刻に置き換えるよう、データベース エンジンに指示します。0 以外の値も指定でき、その場合は 1970 UTC からのナノ秒数として解釈されます。
このキー タイプを利用できるのは Zen v14 からで、対象となるファイル形式は 9.5 から 13.0 です。古いデータベース エンジンで、このタイプを使用するレコードを持つファイルを開こうとすると、認識されない Microkernel ファイルに対するステータス コード 30 が返されます。
AUTOTIMESTAMP 値の範囲は、1970-01-01 00:00:00.000000000 ~ 2554-07-21 23:34:33.709551615 です。
現在の Linux および Android のシステム時計は、真のナノ秒の精度を備えています。Windows では、最も高い精度はセプタ秒(10-7 秒)で、macOS ではマイクロ秒です。ナノ秒の精度に対応していないシステム上で AUTOTIMESTAMP キーが書き込まれた場合、値はゼロで埋められます。その結果、ナノ秒精度でないシステムで挿入または更新を行うと、値が重複する可能性があります。しかし、インデックスが一意となるよう設定されている場合には、データベース エンジンは、以前に生成された最新のタイムスタンプとの一致を検出すると、1 ナノ秒を加算します。重複は、手動で挿入されたタイムスタンプ値や、システム時計のリセットによっても生じる可能性があります。どちらの場合も、Insert(2)または Update(3)はステータス コード 5 で失敗します。
AUTOTIMESTAMP を使用した挿入と更新
Insert(2)および Update(3)オペレーションは、AUTOTIMESTAMP キーのゼロ値を処理する場合、データベース エンジン サーバーのシステム時計から現在のタイムスタンプを取得します。エンジンは、現在のレコード内で、ゼロを含むすべての AUTOTIMESTAMP キーに対してこの値を使用します。
Insert Extended(40)の場合は、エンジンはオペレーション内で指定されたレコードごとに新しいタイムスタンプ値を取得します。AUTOTIMESTAMP キーを一意とした場合、その値が同一オペレーション内で以前に生成されたタイムスタンプ値と一致する場合には、生成された値を 1 ナノ秒ずつ加算することで、レコード間でタイムスタンプが重複しないようにします。Insert(2)と同様に、レコードごとに生成されるタイムスタンプは、当該レコード内のすべての AUTOTIMESTAMP キーに使用されます。
Update Chunk(53)オペレーションで、AUTOTIMESTAMP キーを含むレコードの固定部分に書き込みを行う場合、エンジンは新しいタイムスタンプを取得しません。代わりに、提供されたキー値をそのまま受け入れ、レコードにセットします。したがって、Update Chunk オペレーションを使用するときに、AUTOTIMESTAMP キーを更新するためにゼロ値を指定すると、レコードにゼロ値が格納され、キーは 1970 UTC と解釈されることになります。自動生成されたタイムスタンプでキーを更新したい場合は、Update(3)オペレーションを使用してレコードの固定部分を更新します。
制限
AUTOTIMESTAMP 型のキーを作成する場合には、次の制限が適用されます。
•NOCASE フラグをキーに適用することはできません。
•NULL_KEY および MANUAL_KEY は指定できません。タイムスタンプをインデックスから除外することはできません。
Function Executor および Maintenance ツールでの使い方
Function Executor ツールまたは Maintenance ツールでの AUTOTIMESTAMP キーの使い方は、AUTOINCREMENT キーと似ています。このキーを使用するファイルの場合、キー タイプは Atstamp として一覧に表示されます。また、Atstamp は butil <filename> -stat の出力に表示され、butil -create コマンドのディスクリプション ファイルのキー タイプに使用されます。
BFLOAT
BFLOAT キー タイプは、単精度実数または倍精度実数です。単精度実数は、23 ビットの仮数、128 でバイアスされた 8 ビットの指数、および符号ビットで格納されます。4 バイト float の内部レイアウトは次のとおりです。
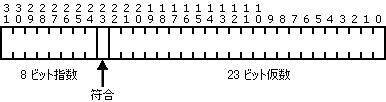
倍精度実数の表現法は、仮数が 23 ビットではなく 55 ビットである点を除いては、単精度実数の表現法と同じです。最小有効数字の 32 ビットは、バイト 0 から 3 に格納されます。
BFLOAT 型は、一般に古い BASIC アプリケーションで使用されます。Microsoft はこのデータ型を MBF(Microsoft Binary Format)と呼びますが、Visual Basic 環境でこの型はサポートしていません。新しいデータベース定義では、BFLOAT ではなく FLOAT を使用する必要があります。
STRING
STRING キー タイプは、左から右へ並んだ文字の連なりです。キー値がヌルであるかどうかを MicroKernel が判定する場合を除いて、各文字は単一バイトに ASCII 形式で表されます。STRING データは、キーのサイズいっぱいになるまで空白を埋め込む必要があります。
CURRENCY
CURRENCY キー タイプは、8 バイトの符号付き数値を表し、Intel バイナリ整数形式で並べ替えられ格納されています。このため、その内部表現法は 8 バイトの INTEGER データ型と同じです。CURRENCY データ型には、小数点以下に 4 桁が想定されており、通貨のデータ値の分数部分を表します。
DATE
DATE キー タイプは、内部的に 4 バイト値として格納されます。日と月はそれぞれ 1 バイトのバイナリ形式で格納されます。年は、年の値全体を表す 2 バイトのバイナリ数です。MicroKernel は、日を 1 番目のバイトに、月を 2 番目のバイトに、年を月に続く 2 バイトの WORD に置きます。
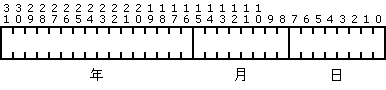
日付フィールドに使用する C 言語の構造体の例を示します。
TYPE dateField {
char day;
char month;
integer year;
}
日付フィールドの year 部には、年全体の整数表現が設定されるようにする必要があります。たとえば、2001 年の場合は 2,001 です。
DECIMAL
DECIMAL キー タイプは、内部的に、1 バイトごとに 2 つの 10 進数を含む、パックされた 10 進数として格納されます。
n バイトの DECIMAL フィールドの内部表現法は次のとおりです。
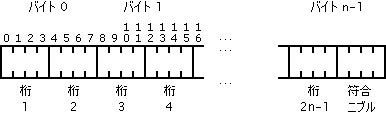
DECIMAL の小数点は暗黙に設定されます。DECIMAL フィールドに小数点は格納されません。DECIMAL フィールドの値の小数点位置のトラッキングはアプリケーションが行います。データベース エンジンがキーを正しく照合するために、DECIMAL キー タイプの値はすべて、小数点以下の桁数を同じにする必要があります。DECIMAL 型は、一般に COBOL アプリケーションで使用されます。
8 バイトの decimal は、15 桁の数字と符号を保持することができます。10 バイトの decimal では、19 桁の数字と符号を保持できます。decimal 値は、左側の桁をゼロで埋める必要があります。
符号ニブルは、正の数の場合は 0xF または 0xC で、負の数の場合は 0xD です。デフォルトで、リレーショナル エンジンおよびそれを使用する SDK アクセス方法の場合、DECIMAL 用の正符号ニブルには常に 0xF を書き込みます。これらは読み取りオペレーションに対し 0xF および 0xC の両方を正として解釈することができます。
レジストリ(Windows レジストリおよび Zen レジストリ)の設定によって、DECIMAL 用の正符号のニブルに対してどのデータベース エンジンを使用するか制御します。デフォルトの正符号ニブルを 0xC に変更する必要がある場合、下記のようにレジストリを編集します。Zen ActiveX アクセス方法では、CommonCOBOLDecimalSign のレジストリ設定に関わらず、正符号ニブルに 0xF を必ず使用することに留意してください。
Windows
レジストリ エディターで、次のキーの CommonCOBOLDecimalSign の値を "YES" に変更します。
HKEY_LOCAL_MACHINE\SOFTWARE\Actian\Zen\SQL Relational Engine
ほとんどの Windows システムで、このキーの場所は HKEY_LOCAL_MACHINE\SOFTWARE\Actian\Zen です。ただし、HKEY_LOCAL_MACHINE\SOFTWARE の下位以降の場所はオペレーティング システムによって異なる可能性があります。
注意: レジストリの編集は高度な操作です。誤って編集すると、オペレーティング システムが起動しなくなる恐れがあります。必要であれば、経験豊富な技術者に依頼して編集を行ってもらってください。Actian Corporation はレジストリの破損に対して責任を負いません。
Linux および macOS
Linux 32 ビット オペレーティング システムの場合、psregedit ユーティリティは次のように指定して実行します。
./psregedit -set -key PS_HKEY_CONFIG/SOFTWARE/Actian/Zen/"SQL Relational Engine" -value "CommonCOBOLDecimalSign" -type PS_REG_STR "YES"
Linux および macOS 64 ビット オペレーティング システムの場合、psregedit ユーティリティは次のように指定して実行します。
./psregedit -set -key PS_HKEY_CONFIG_64/SOFTWARE/Actian/Zen/"SQL Relational Engine" -value "CommonCOBOLDecimalSign" -type PS_REG_STR "YES"
『
Zen User's Guide』の
psregedit も参照してください。
FLOAT
注意: C 言語の定義が FLOAT(4 バイト)または DOUBLE(8 バイト)データ型に対してサポートしている精度を超える精度は失われます。小数点以下の桁数が多い数値に精度が要求される場合は、DECIMAL 型の使用を考慮してください。
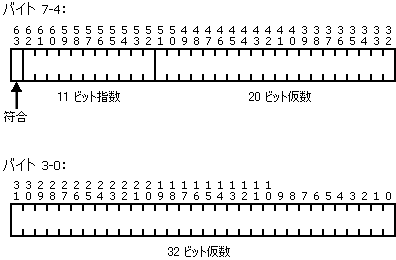
FLOAT キー タイプは、単精度実数または倍精度実数の IEEE 規格に準拠しています。4 バイト FLOAT の内部形式は次のように、23 ビットの仮数、127 でバイアスされた 8 ビットの指数、および符号ビットで構成されます。
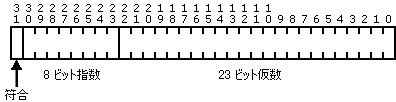
8 バイトの FLOAT キーは、52 ビットの仮数、1023 でバイアスされた 11 ビットの指数、および符号ビットを持ちます。内部形式は次のとおりです。
GUID
GUID キー タイプは 16 バイトの数字で、内部的には 16 バイトのバイナリ値として格納されます。拡張データ型の値は 27 です。
通常、GUID はグローバルな一意識別子として使用されます。これはリレーショナル エンジンの
UNIQUEIDENTIFIER データ型に相当します。
GUID は 9.5 以降のファイル形式を必要とすることに注意してください。
GUID キー
GUID を構成するバイトのソート順序は、10、11、12、13、14、15、8、9、6、7、4、5、0、1、2、3 という順序で比較されます。
GUID のキー セグメント長は 16 バイトにする必要があります。『
Btrieve API Guide』の
キー仕様ブロックを参照してください。
INTEGER
INTEGER キー タイプは、符号付き整数で、偶数バイトを保持する必要があります(1 は例外)。何桁の数字でも含むことができます。INTEGER フィールドは、内部的に Intel バイナリ整数形式で格納され、WORD 内で上位バイトと下位バイトが反転されています。MicroKernel は、キーを右から左へと一度に 1 WORD ずつ評価します。符号は、右端のバイトの上位ビットに格納しなければなりません。INTEGER 型は、ほとんどの開発環境でサポートされています。
表 120 INTEGER キー タイプ
長さ(バイト単位) | 値の範囲 |
|---|
1 | 0 – 255 |
2 | -32768 – 32767 |
4 | -2147483648 – 2147483647 |
8 | -9223372036854775808 – 9223372036854775807 |
LOGICAL
LOGICAL キー タイプは、1 バイト値または 2 バイト値として格納されます。MicroKernel は LOGICAL キー タイプを文字列として照合します。これにより、アプリケーションは、格納されている真または偽を表す値を判定することができます。
LSTRING
LSTRING キー タイプは、文字列の最初のバイトに文字列の長さのバイナリ表現を含む点を除いて、通常の STRING 型と同じ特性を持ちます。LSTRING キー タイプのサイズは、最大 255 バイトに制限されています。LSTRING キーのバイト 0 に格納されている長さにより、有効バイト数が判断されます。データベース エンジンは、値をソートまたは検索する際、指定された文字列の長さを超える値はすべて無視します。LSTRING 型は、一般に古い Pascal アプリケーションで使用されます。
MONEY
MONEY キー タイプの内部表現法は DECIMAL 型と同じですが、小数点以下が 2 桁に想定されます。
NUMERIC
NUMERIC キー タイプの数字はそれぞれ 1 バイトを占めます。NUMERIC 値は、先頭に 0 を付けて右揃えされ、ASCII 文字列として格納されます。右端のバイトには、埋め込み符号が EBCDIC 値で含まれます。デフォルトで、正の NUMERIC データ型の符号値は符号なし数値です。
オプションで、正の NUMERIC データ型の符号の値をシフトするよう指定できます。次の表は、符合値のデフォルト(シフトされていない)状態とシフトされた状態の比較を示します。
表 121 NUMERICS の符合値のシフト状態とシフトなし状態の比較
桁 | デフォルト(シフトなし)の符合値 | シフトされた符合値 |
|---|
| 正 | 負 | 正 | 負 |
|---|
1 | 1 | J | A | J |
2 | 2 | K | B | K |
3 | 3 | L | C | L |
4 | 4 | M | D | M |
5 | 5 | N | E | N |
6 | 6 | O | F | O |
7 | 7 | P | G | P |
8 | 8 | Q | H | Q |
9 | 9 | R | I | R |
0 | 0 | } | { | } |
シフト形式の有効化
シフト形式を有効にするには、Zen データベース エンジンが実行されているマシンで、ある設定を手動で指定しなければなりません。設定 DBCobolNumeric を yes にセットします。このトピックでは、Windows 32 ビット、Linux、および macOS プラットフォームでのこの設定の使用について概説します。
Windows 32 ビット
レジストリ エディターを使用して、DBCobolNumeric 設定を次のキーの文字列値として追加します。
HKEY_LOCAL_MACHINE\SOFTWARE\Actian\Zen\Database Names
DBCobolNumeric の文字列値を yes に設定します。
ほとんどの Windows システムで、このキーの場所は HKEY_LOCAL_MACHINE\SOFTWARE\Actian\Zen ですが、HKEY_LOCAL_MACHINE\SOFTWARE の下位以降の場所はオペレーティング システムによって異なります。
注意: Windows レジストリを誤って編集すると、Windows を起動できなくなる可能性があります。編集は、訓練を受けた IT 担当者のみが行ってください。Actian Corporation は Windows レジストリの破損に対して責任を負いません。
データベース エンジンまたはエンジン サービスを停止して、再起動します。
Linux および macOS
bti.ini の [Database Names] エントリの下に DBCobolNumeric 設定を追加します。
[Database Names]
DBCobolNumeric=yes
デフォルトでは、bti.ini は /usr/local/actianzen/etc ディレクトリにあります。
データベース エンジンを停止して、再起動します。
正の NUMERIC データの符合値の整合
符合値がデフォルト(シフトされていない)形式で含まれている正の NUMERIC データが既にあるかもしれません。DBCobolNumeric を yes に設定した後、引き続き同じテーブルへデータを追加すると、形式が混在することになります。データの符合値の形式を混在させたままにしておくことはお勧めできません。
形式が混在した状態を解消する、あるいは防ぐには、UPDATE ステートメントを使用して、NUMERIC 列をその列自身で更新します。たとえば、テーブル t1 には NUMERIC データ型の列 c1 があるとします。DBCobolNumeric を yes に設定後、c1 を UPDATE TABLE t1 SET c1 = c1 のように更新します。
NUMERICSA
NUMERICSA キー タイプ(NUMERIC SIGNED ASCII と呼ばれることもあります)は、COBOL データ型で、埋め込み符号が EBCDIC 値ではなく ASCII 値である点を除けば、NUMERIC と同じです。
表 122 NUMERICSA の符号値
桁 | デフォルトの符号値 |
|---|
| 正 | 負 |
|---|
1 | 1 または Q | q |
2 | 2 または R | r |
3 | 3 または S | s |
4 | 4 または T | t |
5 | 5 または U | u |
6 | 6 または V | v |
7 | 7 または W | w |
8 | 8 または X | x |
9 | 9 または Y | y |
0 | 0 または P | p |
NUMERICSLB
NUMERICSLB キー タイプ(SIGN LEADING と呼ばれることもあります。COBOL コンパイラ オプション -dcb を使用します)は、COBOL データ型で、NUMERIC データ型の値と似た値を持ちます。NUMERICSLB 値は、先頭に 0 を付けて右揃えされ、ASCII 文字列として格納されます。
表 123 NUMERICSLB の符号値
桁 | デフォルトの符号値 |
|---|
| 正 | 負 |
|---|
1 | 1 | A |
2 | 2 | B |
3 | 3 | C |
4 | 4 | D |
5 | 5 | E |
6 | 6 | F |
7 | 7 | G |
8 | 8 | H |
9 | 9 | I |
0 | 0 | @ |
NUMERICSLS
NUMERICSLS キー タイプ(SIGN LEADING SEPARATE と呼ばれることもあります)は、COBOL データ型で、NUMERIC データ型の値と似た値を持ちます。NUMERICSLS 値は、先頭に 0 を付けて左揃えされ、ASCII 文字列として格納されます。ただし、NUMERICSLS 文字列の左端のバイトは、「+」(ASCII 0x2B)か「-」(ASCII 0x2D)のいずれかになります。この点が、右端のバイトにそのバイトの値と共に符号を埋め込む NUMERIC 値とは異なります。
NUMERICSTB
NUMERICSTB キー タイプ(SIGN TRAILING と呼ばれることもあります。COBOL コンパイラ オプション -dcb を使用します)は、COBOL データ型で、NUMERIC データ型の値と似た値を持ちます。NUMERICSTB 値は、先頭に 0 を付けて右揃えされ、ASCII 文字列として格納されます。
表 124 NUMERICSTB の符号値
桁 | デフォルトの符号値 |
|---|
| 正 | 負 |
|---|
1 | 1 | A |
2 | 2 | B |
3 | 3 | C |
4 | 4 | D |
5 | 5 | E |
6 | 6 | F |
7 | 7 | G |
8 | 8 | H |
9 | 9 | I |
0 | 0 | @ |
NUMERICSTS
NUMERICSTS キー タイプ(SIGN TRAILING SEPARATE と呼ばれることもあります)は、COBOL データ型で、NUMERIC データ型の値と似た値を持ちます。NUMERICSTS 値は、先頭に 0 を付けて右揃えされ、ASCII 文字列として格納されます。ただし、NUMERICSTS 文字列の右端のバイトは、「+」(ASCII 0x2B)か「-」(ASCII 0x2D)のいずれかになります。この点が、右端のバイトにそのバイトの値と共に符号を埋め込む NUMERIC 値とは異なります。
TIME
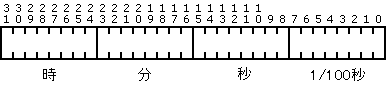
TIME キー タイプは、内部的に 4 バイト値として格納されます。100 分の 1 秒、秒、分、時の値が、それぞれ 1 バイトのバイナリ形式で格納されます。MicroKernel は、100 分の 1 秒の値を最初のバイトに、それ以降のバイトにそれぞれ秒、分、時の値を置きます。データ形式は hh:mm:ss.nn です。サポートされる値の範囲は 00:00:00.00 ~ 23:59:59.99 です。
TIMESTAMP
TIMESTAMP キー タイプは日付と時刻の値を表します。SQL アプリケーションでは、このデータ型を使用して、レコードを最後に更新した現在の日時をレコードにスタンプします。TIMESTAMP 値は、グレゴリオ暦 0001 年 1 月 1 日の世界協定時刻(UTC)から経過したセプタ秒(10^-7 秒)を表す、8 バイトの符号なし値として格納されます。サポートされる値の範囲は、0001-01-01 00:00:00.0000000 ~ 9999-12-31 23:59:59.9999999 です。
AUTOTIMESTAMP とは異なり、値 0 は、新しいレコードが挿入されたとき、または既存のレコードが初めて更新されたときの現在の時刻に自動的に置き換えられません。
メモ:ODBC 標準に従って、CURRENT_TIMESTAMP() や NOW() などのスカラー関数は、データ型のうち小数の秒を表す部分は無視します。これらの関数を使用する際、Zen は小数の秒を無視しないで、3 桁のミリ秒を表示するという点に注意することが重要です。
TIMESTAMP は、構成要素、年、月、日、時、分、秒、およびミリ秒から成る日付と時刻の値をサポートします。次の表は、これらの各構成要素で有効な値の範囲を示しています。
YEAR | 0001 ~ 9999 |
MONTH | 01 ~ 12 |
DAY | 01 ~ 31、グレゴリオ暦の年と月の値によって決められます。 |
HOUR | 00 ~ 23 |
MINUTE | 00 ~ 59 |
SECOND | 00 ~ 59 |
MILLISECOND | 000 ~ 999。デフォルトの設定。小数位は、0 ~ 7(セプタ秒)の値に設定できます。 |
各 TIMESTAMP 値は完全な日付時刻の値を含んでいます。小数位はローカル オペレーティング システムでサポートされる最大の桁数を持ち、必要に応じて末尾のゼロで埋められます。値が返されるとき、この値はタイムスタンプに対して設定された小数位を使用します。たとえば、小数位が 3 の場合はマイクロ秒で返され、小数位が 6 の場合はミリ秒で返されます。
日付データ型および時刻データ型の小数位の詳細については、
タイムスタンプ データ型の小数位と返される関数値を参照してください。
現地時刻で TIMESTAMP の値を指定すると、リレーショナル エンジンはそれを UTC(Coordinated Universal Time)に変換してからレコードに格納します。TIMESTAMP 値を要求すると、リレーショナル エンジンは値を現地時刻に変換して返します。
注意: データベース エンジンを実行するコンピューターのタイム ゾーン情報が正しく設定されていることが重要です。タイム ゾーンを移動するか、タイム ゾーン情報を変更した場合、返されるデータは UTC から現地時刻に変換されるときに変わります。現地時刻および UTC の変換は、リレーショナル エンジン内で、リレーショナル エンジンが動作している場所のタイム ゾーン情報を使用して発生します。リレーショナル エンジンとタイム ゾーンが異なるセッションのタイム ゾーン情報は、現地時刻および UTC の変換には使用されません。
タイムスタンプ データは格納する前に変換されるため、TIMESTAMP 型は、データベース本体の外にあるイベントを参照する現地時刻データや現地日付データでの使用には向きません。特に、季節時間の変更が行われるタイム ゾーン(米国のサマー タイムなど)ではそうです。
たとえば、10 月 15 日に、11 月 15 日午前 10 時の予定を記録するタイムスタンプ値を入力したとします。タイム ゾーンは U.S. 中部であるとします。リレーショナル エンジンは値を格納するとき、現在の現地時刻情報を使って値を UTC に変換します(CDT の場合、UTC - 5 時間)。したがって、時間値 15 が格納されます。11 月 1 日に予定の時刻を確認するとします。現在、お使いのコンピューターは標準時間になっています。これは、10 月にサマー タイムの切り替えが発生したためです。これにより、変換は(UTC - 6 時間)になります。予定時刻を抽出すると、現地時刻の午前 9 時(15 UTC - 6 CST)が表示されますが、これは正しい予定時刻ではありません。
データベース エンジンをあるタイム ゾーンから別のタイム ゾーンに移動させた場合も、同種の問題が発生します。
リレーショナル エンジンは、DATE 値および TIME 値を UTC に変換しないので、外部データを記録する場合は、できる限りいつも DATE 列および TIME 列を使用することをお勧めします。TIMESTAMP 列を使用する唯一の理由は、データベースに入力したレコードの時間順を判定する固有の機能に必要だからです。
Function Executor および Maintenance ツールでの使い方
Function Executor ツールまたは Maintenance ツールでの TIMESTAMP キーの使い方は、AUTOINCREMENT キーと似ています。このキーを使用するファイルの場合、キー タイプは Tstamp として一覧に表示されます。また、Tstamp は butil <filename> -stat の出力に表示され、butil -create コマンドのディスクリプション ファイルのキー タイプに使用されます。
TIMESTAMP2
TIMESTAMP2 キー タイプは、Unix エポックに基づいてナノ秒単位で時間を追跡します。SQL アプリケーションでは、このデータ型を使用して、レコードを最後に更新した現在の日時をレコードにスタンプします。値は、グレゴリオ暦 1970 年 1 月 1 日の世界協定時刻(UTC)から経過したナノ秒(10^-9 秒)を表す、8 バイトの符号なし値として格納されます。サポートされる値の範囲は、1970-01-01 00:00:00.000000000 ~ 2554-07-21 23:34:33.709551615 です。
AUTOTIMESTAMP とは異なり、値 0 は、新しいレコードが挿入されたとき、または既存のレコードが初めて更新されたときの現在の時刻に自動的に置き換えられません。
このキー タイプを利用できるのは Zen v14 SP1 からで、対象となるファイル形式は 9.5 から 13.0 です。古いデータベース エンジンで、このタイプを使用するレコードを持つファイルを開こうとすると、認識されない Microkernel ファイルに対するステータス コード 30 が返されます。
メモ:ODBC 標準に従って、CURRENT_TIMESTAMP() や NOW() などのスカラー関数は、データ型のうち小数の秒を表す部分は無視します。これらの関数を使用する際、Zen は小数の秒を無視しないで、9 桁のナノ秒を表示するという点に注意することが重要です。
TIMESTAMP2 は、構成要素、年、月、日、時、分、秒、およびナノ秒から成る日付と時刻の値をサポートします。次の表は、これらの各構成要素で有効な値の範囲を示しています。
YEAR | 1970 ~ 2554 |
MONTH | 01 ~ 12 |
DAY | 01 ~ 31、グレゴリオ暦の年と月の値によって決められます。 |
HOUR | 00 ~ 23 |
MINUTE | 00 ~ 59 |
SECOND | 00 ~ 59 |
NANOSECOND | 000000000 ~ 999999999デフォルトの設定。 |
各 TIMESTAMP2 値は完全な日付時刻の値を含んでいます。小数位はローカル オペレーティング システムでサポートされる最大の桁数を持ち、必要に応じて末尾のゼロで埋められます。値が返されるとき、この値はタイムスタンプに対して設定された小数位を使用します。たとえば、小数位が 3 の場合はマイクロ秒で返され、小数位が 6 の場合はミリ秒で返されます。
日付データ型および時刻データ型の小数位の詳細については、
タイムスタンプ データ型の小数位と返される関数値を参照してください。
現地時刻で TIMESTAMP2 の値を指定すると、リレーショナル エンジンはそれを UTC(Coordinated Universal Time)に変換してからレコードに格納します。TIMESTAMP2 値を要求すると、リレーショナル エンジンは値を現地時刻に変換して返します。
注意: データベース エンジンを実行するコンピューターのタイム ゾーン情報が正しく設定されていることが重要です。タイム ゾーンを移動するか、タイム ゾーン情報を変更した場合、返されるデータは UTC から現地時刻に変換されるときに変わります。現地時刻および UTC の変換は、リレーショナル エンジン内で、リレーショナル エンジンが動作している場所のタイム ゾーン情報を使用して発生します。リレーショナル エンジンとタイム ゾーンが異なるセッションのタイム ゾーン情報は、現地時刻および UTC の変換には使用されません。
タイムスタンプ データは格納する前に変換されるため、TIMESTAMP2 型は、データベース本体の外にあるイベントを参照する現地時刻データや現地日付データでの使用には向きません。特に、季節時間の変更が行われるタイム ゾーン(米国のサマー タイムなど)ではそうです。
たとえば、10 月 15 日に、11 月 15 日午前 10 時の予定を記録するタイムスタンプ値を入力したとします。タイム ゾーンは U.S. 中部であるとします。リレーショナル エンジンは値を格納するとき、現在の現地時刻情報を使って値を UTC に変換します(CDT の場合、UTC - 5 時間)。したがって、時間値 15 が格納されます。11 月 1 日に予定の時刻を確認するとします。現在、お使いのコンピューターは標準時間になっています。これは、10 月にサマー タイムの切り替えが発生したためです。これにより、変換は(UTC - 6 時間)になります。予定時刻を抽出すると、現地時刻の午前 9 時(15 UTC - 6 CST)が表示されますが、これは正しい予定時刻ではありません。
データベース エンジンをあるタイム ゾーンから別のタイム ゾーンに移動させた場合も、同種の問題が発生します。
リレーショナル エンジンは、DATE 値および TIME 値を UTC に変換しないので、外部データを記録する場合は、できる限りいつも DATE 列および TIME 列を使用することをお勧めします。TIMESTAMP2 列を使用する唯一の理由は、データベースに入力したレコードの時間順を判定する固有の機能に必要だからです。
Function Executor および Maintenance ツールでの使い方
Function Executor ツールまたは Maintenance ツールでの TIMESTAMP2 キーの使い方は、AUTOINCREMENT キーと似ています。このキーを使用するファイルの場合、キー タイプは TS2 として一覧に表示されます。また、TS2 は butil <filename> -stat の出力に表示され、butil -create コマンドのディスクリプション ファイルのキー タイプに使用されます。
UNSIGNED BINARY
UNSIGNED BINARY キーは、キーの最大長である 255 バイトまでであれば何バイトにでもできます。UNSIGNED キーは、上位バイトから下位バイトへと 1 バイトごとに比較されます。キーの最初のバイトが下位バイトです。キーの最後のバイトが上位バイトです。
データベース エンジンは、UNSIGNED BINARY キーを符号なしの INTEGER キーとしてソートします。これらのキーの違いは、INTEGER には符号ビットがあるのに対し、UNSIGNED BINARY タイプにはないという点と、UNSIGNED BINARY キーは 4 バイトより長くすることができるという点です。
WSTRING
WSTRING は、ヌルで終わらない Unicode 文字列です。文字列の長さはフィールドの長さで決まります。
WZSTRING
WZSTRING は、2 つのヌルで終わる Unicode 文字列です。文字列の長さは、フィールド内の Unicode NULL(2 ヌル バイト)の位置で決まります。これは、Btrieve でサポートされる
ZSTRING 型に対応します。
ZSTRING
ZSTRING キー タイプは、C 文字列に対応します。ZSTRING 型は、バイナリ 0 を含むバイトで終わるという点以外は、通常の文字列型と同じ特性を持ちます。MicroKernel は、キー値がヌルかどうかを判定する場合を除き、ZSTRING 内で見つけた最初のバイナリ 0 より後の値をすべて無視します。
ZSTRING 型の最大長は、ヌル終端文字を含めて、255 バイトです。ヌル値を許可する列のキーとして使用する場合、文字列の先頭 254 バイトのみがキーに使用されます。このわずかな制限は、キーの合計長が 255 バイトに制限されていることにより生じるもので、1 バイトは列のヌル インジケータが占めるため、残り 254 バイトだけがキー値になります。
キーでないデータ型
このトピックでは、インデックスを設定できない(Btrieve キーとして使用できない)データ型の内部記憶形式について説明します。
BLOB
バイナリ ラージ オブジェクト(BLOB)タイプは、最大 2 GB までのサイズのバイナリ データ フィールドのサポートを提供します。このタイプは 2 つの部分から成ります。
•レコードの固定長部分での 8 バイト ヘッダー。ヘッダーには、レコードの可変長部分におけるデータの開始位置のオフセットを示す 4 バイト整数と、そのデータのサイズを示す 4 バイト整数が含まれます。
•レコードの可変長部分内に格納されているバイナリ データ自体。すべての BLOB および CLOB フィールドのサイズの合計は 2 GB 以下である必要があります。これは、レコードの可変長部分へのオフセット ポインターが、最大 2 GB オフセットに制限されているためです。最大サイズ 2 GB の BLOB を格納するには、レコード中に BLOB または CLOB フィールドは 1 つしか定義できません。
CLOB
文字ラージ オブジェクト(CLOB)タイプは、最大 2 GB までのサイズの文字列データ フィールドのサポートを提供します。このタイプは 2 つの部分から成ります。
•レコードの固定長部分での 8 バイト ヘッダー。ヘッダーには、レコードの可変長部分におけるデータの開始位置のオフセットを示す 4 バイト整数と、そのデータのサイズ(バイト単位)を示す 4 バイト整数が含まれます。
•レコードの可変長部分内に格納されている文字データ自体。すべての BLOB および CLOB フィールドのサイズの合計は 2 GB 以下である必要があります。これは、レコードの可変長部分へのオフセット ポインターが、最大 2 GB オフセットに制限されているためです。最大サイズ 2 GB の BLOB を格納するには、レコード中に BLOB または CLOB フィールドは 1 つしか定義できません。