高度な機能
この章には、データ プロバイダーの高度な機能を説明する以下のセクションが含まれます。
接続プールの使用
接続プールを使用すれば、作成済みの接続を再利用できるので、データ プロバイダーはデータベースに接続するたびに新しい接続を作成する必要がなくなります。データ プロバイダーでは .NET クライアント アプリケーションで自動的に接続プールを使用できるようになりました。
接続プールの動作は、接続文字列オプションによって制御することができます。たとえば、接続プール数、プール内の接続数、接続が破棄されるまでの時間(秒数)を定義することができます。
ADO.NET の接続プールは .NET Framework によって提供されません。ADO.NET データ プロバイダー自体に実装する必要があります。
接続プールの作成
各接続プールは、それぞれ特有の接続文字列と関連付けられます。デフォルトでは、接続プールは一意な接続文字列を使って最初にデータベースに接続したときに作成されます。プールには、プールの最小限のサイズまで接続が格納されます。プールが最大限のサイズに達するまで、接続がプールに追加されていきます。
プールは、その中で接続が開いている限り、あるいは、Connection オブジェクトへの参照を持つアプリケーションによって使用されており、そのオブジェクトに開いている接続がある限り、アクティブであり続けます。
新しい接続を開いたとき、その接続文字列が既存のプールと一致しない場合は、新しいプールを作成する必要があります。同じ接続文字列を使用することで、アプリケーションのパフォーマンスやスケーラビリティを向上させることができます。
以下の C# コード例では、3 つの新しい PsqlConnection オブジェクトが作成されます。ただし、これらのオブジェクトを管理するために必要な接続プールは 2 つのみです。1 番目と 2 番目の接続文字列では、ユーザー ID とパスワードに割り当てられる値だけが異なることに注意してください。
DbProviderFactory Factory = DbProviderFactories.GetFactory("Pervasive.Data.SqlClient");
DbConnection conn1 = Factory.CreateConnection();
conn1.ConnectionString = "Server DSN=DEMODATA;User ID=test;
Password=test;Host=localhost;"conn1.Open();
// プール A が作成されます
DbConnection conn2 = Factory.CreateConnection();
conn2.ConnectionString = "Server DSN=DEMODATA2;User ID=lucy;
Password=quake;Host=localhost;"
conn2.Open();
// 接続文字列が異なるため、プール B が作成されます
DbConnection conn3 = Factory.CreateConnection();
conn3.ConnectionString = "Server DSN=DEMODATA;User ID=test;
Password=test;Host=localhost;"
conn3.Open();
// conn3 は conn1 と一緒にプール A に入ります
プールへの接続の追加
接続プールは、アプリケーションが使用する一意な接続文字列を作成している最中に作成されます。プールが作成されると、Min Pool Size 接続文字列オプションによって設定される、プールの必要最小限のサイズ条件を満たすだけの接続がプールに格納されます。アプリケーションが Min Pool Size を超える接続を使用する場合、データ プロバイダーは Max Pool Size 接続文字列オプション(プール内の最大接続数を設定します)の値になるまで、プールに接続を追加割り当てします。
Connection.Open(...) メソッドを呼び出すアプリケーションで Connection オブジェクトが要求されたとき、プールから使用可能な接続が入手できる場合には、接続はプールから取得されます。使用可能な接続とは、現在ほかの有効な Connection オブジェクトによって使用されておらず、合致する分散トランザクション コンテキストを持ち(妥当な場合)、サーバーへの有効なリンクを持っている接続と定義付けられます。
プールの最大サイズに達し、かつ入手できる使用可能な接続がない場合には、要求はデータ プロバイダーのキューに入れられます。データ プロバイダーは使用可能な接続をアプリケーションへ返すために、Connection Timeout 接続文字列オプションの値が示す時間だけ待ちます。この時間が経過しても接続が入手可能にならなかった場合は、データ プロバイダーはアプリケーションにエラーを返します。
データ プロバイダーに対し、プールされている接続数に影響を与えないで、指定したプールの最大サイズを超える接続を作成できるようにすることができます。これはたとえば、時折発生する接続要求の急増を処理する場合などに有用です。Max Pool Size Behavior 接続文字列オプションを SoftCap に設定することにより、作成される接続数は Max Pool Size に設定された値を超えることが可能になりますが、プールされる接続数は設定値を超えません。プールの最大接続数が使用されている場合、データ プロバイダーは新しい接続を作成します。接続がプールに返されたとき、そのプールにアイドル状態の接続が入っている場合には、プール メカニズムは接続プールが Max Pool Size を決して超えないよう、破棄する接続を選択します。Max Pool Size Behavior を HardCap に設定した場合、作成される接続数は Max Pool Size に設定された値を超えません。
重要:PsqlConnection オブジェクトの Close() または Dispose() メソッドを使用して接続を閉じると、その接続はプールに追加されるか戻されます。アプリケーションで Close() メソッドを使用した場合、接続文字列の設定は Open() メソッドを呼び出す前の状態にとどまります。Dispose メソッドを使用して接続を閉じた場合には、接続文字列の設定は消去され、デフォルトの設定に戻されます。
プールからの接続の削除
接続プールから接続が削除されるのは、Load Balance Timeout 接続文字列オプションで決められた存続時間が過ぎた場合や、接続文字列の一致する新しい接続がアプリケーションによって開始された(PsqlConnection.Open() が呼び出された)場合です。
接続プールの接続をアプリケーションに返す前に、プール マネージャーはその接続がサーバー側で閉じられているかどうかを確認します。接続が有効でなくなっていれば、プール マネージャーはその接続を破棄し、プールから別の入手可能で有効な接続を返します。
再使用するための接続プールから接続をどのような順序で削除するかを、Connection Pool Behavior 接続文字列オプションを用いて、接続の使用頻度または使用時期を基に制御することができます。接続をバランスよく使用するには、LeastFrequentlyUsed 値または LeastRecentlyUsed 値を使用します。あるいは、毎回同じ接続を使用した方がパフォーマンスが良くなるアプリケーションの場合は、MostFrequentlyUsed 値または MostRecentlyUsed 値を使用できます。
Connection オブジェクトの ClearPool メソッドおよび ClearAllPools メソッドは、接続プールからすべての接続を削除します。ClearPool は特定の接続に関連付けられている接続プールを空にします。対照的に、ClearAllPools はデータ プロバイダーによって使用されるすべての接続プールを空にします。メソッドを呼び出すときに使用中だった接続は、閉じるときに破棄されます。
メモ:デフォルトで、無効な接続を破棄することによって、接続数が Min Pool Size 属性で指定した数より少なくなった場合、新しい接続はアプリケーションで必要になるまで作成されません。
プール内の停止接続の処理
アイドル状態の接続が、そのデータベースへの物理的接続を失った場合には何が起こるのでしょうか。たとえば、データベース サーバーが再起動されたり、ネットワークが一時的に中断されるとします。プール内の既存の Connection オブジェクトを使って接続しようとするアプリケーションは、データベースへの物理的接続が失われているため、エラーを受け取る可能性があります。
Control Centerはこの状況をユーザーに意識させないで処理します。Connection.Open() では、データ プロバイダーは単に接続プールから接続を返すだけなので、アプリケーションはこのとき何のエラーも受け取りません。SQL ステートメントを実行するために Connection オブジェクトが初めて使用されたとき(たとえば、Command オブジェクトの Execute メソッドを介して)、データ プロバイダーはサーバーへの物理的接続が失われていることを検出し、SQL ステートメントを実行する
前にサーバーへの再接続を試みます。データ プロバイダーがサーバーへ再接続できた場合、アプリケーションには SQL の実行結果が返され、エラーは何も返されません。データ プロバイダーはこのシームレスな再接続を試みる際、接続フェールオーバー オプションが有効になっていればそれを利用します。プライマリ サーバーが使用できないときはバックアップ サーバーへ接続するようデータ プロバイダーを構成する方法については、
接続フェールオーバーの使用を参照してください。
メモ:データ プロバイダーは、SQL ステートメントの実行時にデータベース サーバーへの再接続を試みることができるため、ステートメントが実行されるときに接続エラーをアプリケーションへ返すことができます。データ プロバイダーがサーバーに再接続できない(たとえば、サーバーがまだダウンしている)場合、実行メソッドは再接続の試行が失敗したことと、その接続が失敗した理由の詳細を知らせるエラーをスローします。
この接続プール内の停止接続を処理する技術には、接続プール メカニズムを超越して最高のパフォーマンスを得られるという効果があります。一部のデータ プロバイダーは、接続がアイドル状態である間、ダミーの SQL ステートメントを使って定期的にサーバーに ping を実行します。その他のデータ プロバイダーは、アプリケーションから接続プール内の接続の使用を要求されたときにサーバーに ping を実行します。これらの手法はいずれもデータベース サーバーへの往復を追加するため、結局のところ、アプリケーションの通常の操作が発生している間ずっと、アプリケーションの速度が落ちます。
接続プールのパフォーマンスの追跡
データ プロバイダーは、このデータ プロバイダーを使用するアプリケーションの調整およびデバッグが行える PerfMon カウンターのセットをインストールします。PerfMon カウンターの詳細については、
PerfMon のサポートを参照してください。
ステートメント キャッシングの使用
ステートメント キャッシュは、プリペアド ステートメントのグループまたは Command オブジェクトのインスタンスで、アプリケーションによって再使用が可能です。ステートメント キャッシュを使用するとアプリケーションのパフォーマンスを向上させることができます。これは、プリペアド ステートメントの動作が、そのステートメントがアプリケーションの存続期間中に何度再使用されたとしても、1 度だけ実行されるためです。キャッシュ内のステートメントの有効性を分析することができます(
接続統計情報によるパフォーマンスの分析を参照してください)。
ステートメント キャッシュは物理接続に属します。実行された後、プリペアド ステートメントはステートメント キャッシュに置かれ、接続が閉じられるまで保持されます。
ステートメント キャッシングは複数のデータ ソース間で使用できるほか、Data Access Application Block を含む Microsoft Enterprise Library などの抽象化技術の下で使用できます。
ステートメント キャッシングの有効化
デフォルトで、ステートメント キャッシングは無効になっています。既存のアプリケーションのステートメント キャッシングを有効にするには、Statement Cache Mode 接続文字列オプションを Auto に設定します。この場合は、すべてのステートメントをステートメント キャッシュに置くことができます。
キャッシュすると明示的にマークしたステートメントのみをステートメント キャッシュに置くように、ステートメント キャッシングを設定することもできます。これを行うには、そのステートメントの Command オブジェクトの StatementCacheBehavior プロパティに Cache を設定し、Statement Cache Mode 接続文字列オプションに ExplicitOnly を設定します。
表
2 はステートメント キャッシング設定とその影響を要約したものです。
表 2 ステートメント キャッシュ動作の要約
動作 | StatementCacheBehavior | Statement Cache Mode |
|---|
ステートメントを明示的にステートメント キャッシュに追加します。 | Cache | ExplicitOnly(デフォルト) |
ステートメントをステートメント キャッシュに追加します。必要に応じ、ステートメントは、Cache とマークされたステートメント用の場所を空けるために削除されます。 | Implicit(デフォルト) | Auto |
ステートメントをステートメント キャッシュから明確に除外します。 | DoNotCache | Auto または ExplicitOnly |
ステートメント キャッシング手法の選択
ステートメント キャッシングを使用すると、アプリケーションの存続期間中にプリペアド ステートメントを複数回再使用するアプリケーションはパフォーマンスが向上します。ステートメント キャッシュのサイズは Max Statement Cache Size 接続文字列オプションに設定します。ステートメント キャッシュのスペースが限られている場合は、1 度しか使用されないプリペアド ステートメントをキャッシュしないでください。
アプリケーションが使用する全プリペアド ステートメントをキャッシュすれば、最高のパフォーマンスを提供できるように思われます。しかし、この手法では、接続プールを使ってステートメント キャッシングを実装した場合、データベースのメモリに負担をかける結果になります。この場合、プールされた接続はそれぞれステートメント キャッシュを持ち、アプリケーションが使用する全プリペアド ステートメントを含むことになります。これらのプールされたプリペアド ステートメントは、すべてデータベースのメモリにも保持されます。
接続フェールオーバーの使用
接続フェールオーバーによって、ハードウェア障害やトラフィックの過負荷などが原因でプライマリ データベース サーバーが利用できなくなった場合でも、アプリケーションは代替またはバックアップ データベース サーバーに接続することができます。接続フェールオーバーは、重要な .NET アプリケーションが依存するデータを常に使用可能な状態にします。
プライマリ サーバーが接続を受け入れない場合に接続を試行する代替データベースのリストを設定することで、データ プロバイダーにおける接続フェールオーバー機能をカスタマイズすることができます。接続が成功するまで、あるいはすべての代替データベースへの接続を指定した回数試行するまで、接続の試行が続けられます。
たとえば、図
1 は複数のデータベース サーバーを持つ環境を示しています。データベース サーバー A はプライマリ データベース サーバー、データベース サーバー B は 1 番目の代替サーバー、そしてデータベース サーバー C は 2 番目の代替サーバーとして設計されています。
図 1 接続フェールオーバー
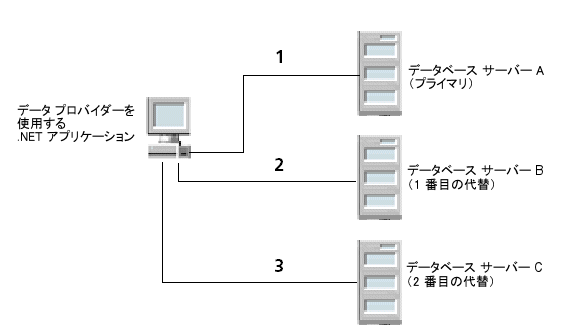
まず、アプリケーションはプライマリ データベースであるデータベース サーバー A(1)に接続を試みます。接続フェールオーバー機能を有効にすると、アプリケーションがデータベース サーバー A に接続できなかった場合はデータベース サーバー B(2)に接続を試みます。その接続の試行も失敗した場合、アプリケーションはデータベース サーバー C(3)に接続を試みます。
このシナリオで、最低でもどれか 1 つのサーバーへは接続できると思われますが、接続にすべて失敗した場合、データ プロバイダーはプライマリ サーバーと各代替データベースに対し指定の回数分だけ接続を再試行させることができます。
接続の再試行(
Connection Retry Count)機能を使用すれば、試行回数を指定することができます。
接続の試行間隔(
Connection Retry Delay)機能を使用すれば、接続の試行間隔を秒数で指定することもできます。接続の再試行の詳細については、
接続の再試行機能の使用を参照してください。
データ プロバイダーは、現在対象としている代替サーバーとの通信が確立できなかった場合にのみ、次の代替サーバーへフェールオーバーします。データ プロバイダーがデータベースとの通信に成功したが、ログイン情報が正しくないなどの原因でそのデータベースが接続要求を拒否した場合、データ プロバイダーは例外を生成し、代替サーバー リスト内の次のデータベースへは接続を試行しません。これは、各代替サーバーがプライマリ サーバーのミラーであり、認証パラメーターや関連情報がすべて同じであることが前提です。
接続フェールオーバーでは新しい接続のみを保護し、トランザクションやクエリの状態は保持しません。ご使用のデータ プロバイダーにおける接続フェールオーバーの設定の詳細については、
接続フェールオーバーの設定を参照してください。
クライアント ロード バランスの使用
クライアント ロード バランスは接続フェールオーバーと共に動作してユーザーの環境で新しい接続を分散することで、接続要求に対応できないサーバーがないようにします。接続フェールオーバーとクライアント ロード バランスがどちらも有効な場合、プライマリ データベースおよび代替データベースへ接続が試行される順序はランダムです。
たとえば、図
2 で示すようにクライアント ロード バランスが有効になっているとします。
図 2 クライアント ロード バランスの例
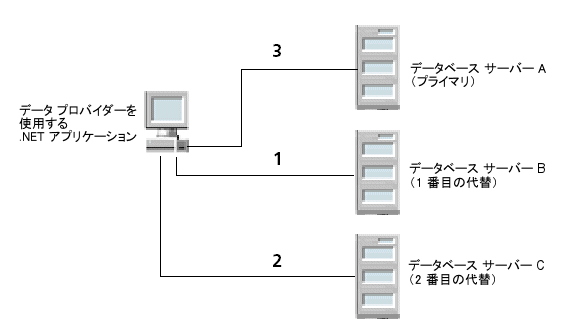
まず、データベース サーバー B への接続が試行されます(1)。それからデータベース サーバー C への接続が試行され(2)、続いてデータベース サーバー Aへの接続が試行されます(3)。その後、これと同じ順序で接続が試行されます。対照的に、このシナリオでクライアント ロード バランスが無効だった場合、各データベースへの接続の試行はシーケンシャルな順序で行われます。つまり、最初にプライマリ サーバーに試行したら、その後は代替サーバー リスト内のエントリ順に基づいて代替サーバーに試行します。
ご使用のデータ プロバイダーにおけるクライアントとロード バランスの設定の詳細については、
接続フェールオーバーの設定を参照してください。
接続の再試行機能の使用
接続の再試行では、データ プロバイダーが最初の接続の試行に失敗した後に、プライマリ サーバーおよび(設定している場合)代替サーバーへ接続を試行する回数を定義します。接続の再試行は、システム復旧の有力な方策となります。たとえば、停電などの電力障害によりクライアントとサーバーの両方が動作しなくなってしまうシナリオを考えてみましょう。電力が復旧してすべてのコンピューターが再起動される際、サーバーが自身のスタートアップ ルーチンを完了する前にクライアントがそのサーバーに接続しようとするかもしれません。接続の再試行が有効な場合、クライアント アプリケーションは、サーバー側で接続が正しく受け入れられるようになるまで接続を何度も試行し続けることができます。
接続の再試行は、サーバーが 1 つしかない環境でも使用できますが、複数サーバーを持つ環境における接続フェールオーバー シナリオの補完機能としても使用できます。
接続文字列オプションを使用すると、データ プロバイダーが接続を試行する回数や接続の試行間隔を秒単位で指定できます。接続の再試行に対する設定の詳細については、
接続フェールオーバーの設定を参照してください。
接続フェールオーバーの設定
接続フェールオーバーによって、ハードウェア障害やトラフィックの過負荷などが原因でプライマリ データベース サーバーが利用できなくなった場合でも、アプリケーションは代替またはバックアップ データベース サーバーに接続することができます。
接続フェールオーバーに関する詳細については、
接続フェールオーバーの使用を参照してください。
接続フェールオーバーを別のサーバーに構成するには、プライマリ サーバーが接続を受け入れない場合に接続を試行する代替データベース サーバーのリストを指定する必要があります。これを行うには Alternate Servers 接続文字列オプションを使用します。接続の確立に成功するまで、あるいはリストにエントリされるすべての代替データベースへの接続を 1 回ずつ試行(デフォルト)するまで、接続の試行が続けられます。
任意で、以下の接続フェールオーバー機能も指定することができます。
•データ プロバイダーが最初に接続を試行した後に、プライマリ サーバーおよび代替サーバーへ接続を試行する回数。デフォルトでは、データ プロバイダーは接続を再試行しません。この機能を設定するには Connection Retry Count 接続文字列オプションを使用します。
•プライマリ サーバーと代替サーバーへの接続の試行間隔(秒数)。デフォルトの間隔は 3 秒です。この機能を設定するには Connection Retry Delay 接続文字列オプションを使用します。
•データ プロバイダーがプライマリ サーバーおよび代替サーバーへの接続を試行する際、ロード バランスを使用するかどうか。ロード バランスが有効な場合、データ プロバイダーは接続の試行順序のパターンをシーケンシャルではなくランダムにします。デフォルトでは、ロード バランスは使用されません。この機能を設定するには Load Balancing 接続文字列オプションを使用します。
接続文字列を使用して、データ プロバイダーに対し接続フェールオーバーを使用するよう指示します。
接続文字列の使用 を参照してください。
次の C# コードには、データ プロバイダーで接続フェールオーバー機能と、その接続オプションであるロード バランス、接続の再試行、および接続の再試行の間隔をすべて使用するように設定する接続文字列が含まれています。
Conn = new PsqlConnection Conn = new PsqlConnection();
Conn = new PsqlConnection("Host=myServer;User ID=test;Password=secret;
Server DSN=SERVERDEMO;Alternate Servers="Host=AcctServer, Host=AcctServer2";
Connection Retry Count=4;Connection Retry Delay=5;Load Balancing=true;
Connection Timeout=60")
具体的に説明すると、この接続文字列の設定は、データ プロバイダーで 2 つの代替サーバーを接続フェールオーバー サーバーとして使用すること、最初の接続の試行に失敗した場合はさらに 4 回接続を再試行すること、試行間隔は 5 秒間とし、プライマリ サーバーと代替サーバーへの接続の試行順序はランダムとすることを示しています。接続の試行は 1 回当り 60 秒間持続し、試行する順序は最初に行ったランダム順序がそのまま最後まで使用されます。
セキュリティの設定
データ プロバイダーは、接続での暗号化されたネットワーク通信(ワイヤ暗号化とも呼ばれます)をサポートします。デフォルトでは、データ プロバイダーはサーバーの設定を反映します。暗号化設定の詳細については、表
28 を参照してください。
データ プロバイダーで許可される暗号化のレベルは、使用される暗号化モジュールによって異なります。デフォルトの暗号化モジュールでは、データ プロバイダーは 40 ビット、56 ビット、および 128 ビット暗号化をサポートしています。
データ暗号化は、データの暗号化と復号で必要となる追加オーバーヘッド(主に CPU 使用)のため、パフォーマンスに悪影響を与えることがあります。
暗号化に加え、Control Centerは .NET Framework で定義されるセキュリティ権限を通してセキュリティを実装します。
コードへのアクセス権限
データ プロバイダーをロードして実行するためには、FullTrust 権限を設定する必要があります。これは、System.Data のクラスが FullTrust 権限を継承しなければならないためです。これらのクラスは、すべての ADO.NET データ プロバイダーで DataAdapter を実装するために必要です。
セキュリティの属性
データ プロバイダーには AllowPartiallyTrustedCallers 属性がマークされています。
Zen Bulk Load の使用
Zen Bulk Load は、すべてのバルク ロードの要求に対して 1 か所ですべてを行えるワンストップ手法を提供します。これは、Zen およびこのバルク ロード機能をサポートするすべての DataDirect Connect 製品にバルク ロード操作を行う上で単純かつ一貫性があります。つまり、標準ベースの API バルク インターフェイスを使用してバルク ロード アプリケーションを記述し、それから、その仕事を実行するためにすぐにデータベースのデータ プロバイダーまたはドライバーをプラグインすることができます。
データを Zen、Oracle、DB2、および Sybase にロードする必要があるとします。これまでは、バルク ロード操作のためにデータベース ベンダー製のツールを使用するか、独自のツールを作成する必要がありました。今では、Zen Bulk Load に組み込まれた相互運用性により、作業は非常に簡単になりました。もう 1 つの利点は、Zen Bulk Load は 100% マネージ コードを使用するため、ほかのベンダー製の基盤となるユーティリティやライブラリを必要としないことです。
異なるデータ ストア間でのバルク ロード操作は、クエリの結果をカンマ区切り値(CSV)形式ファイルであるバルク ロード データ ファイルに残すことによって完成されます。このファイルは、Control Center と、バルク ロードをサポートする DataDirect Connect for ADO.NET データ プロバイダー間で使用できます。さらに、バルク ロード データ ファイルは、DataDirect Connect 製品やバルク ロード機能をサポートするデータ プロバイダーで使用できます。たとえば、Zen データ プロバイダーで生成された CSV ファイルは、バルク ロード対応の DataDirect Connect forODBC ドライバーで使用できます。
Zen Bulk Load で使用するシナリオ
Control Centerで Zen Bulk Load を使用する方法は 2 つあります。
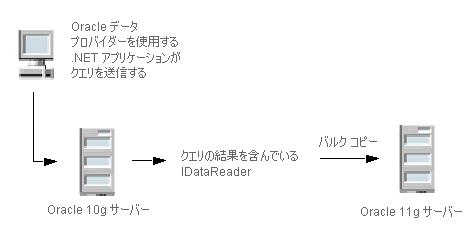
•新しい Zen バージョンにアップグレードし、図
3 に示すように、古い Zen データ ソースから新しいデータ ソースへデータをコピーします。
図 3 2 つのデータ ソース間での Zen Bulk Load の使用
•データベースからデータをエクスポートし、その結果を Zen データベースに移行します。図
4 は、データを ADO.NET データベース サーバーにコピーする ODBC 環境を示しています。
図 4 ODBC から ADO.NET へのデータのコピー
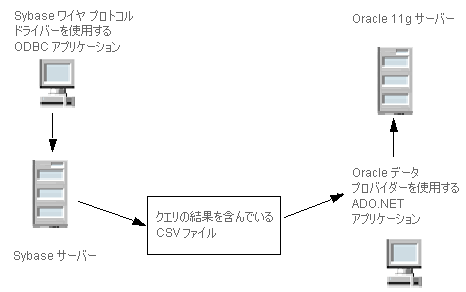
この図で、ODBC アプリケーションは CSV ファイルへデータをエクスポートするコードを含み、ADO.NET アプリケーションは CSV ファイルを指定して開くコードを含みます。Control Centerおよび DataDirect ODBC ドライバーは一貫した形式を使用するため、これらの標準インターフェイスを介して相互運用性がサポートされます。
Zen Common Assembly
ADO.NET 用の Zen BulkLoad の実装は、事実上の業界標準である Microsoft SqlBulkCopy クラスの定義を使用し、強力な組み込み機能を追加してバルク操作の信頼性をより高めるため、柔軟性に加えて相互運用性も高めます。
データ プロバイダーには、Zen Bulk Load をサポートするためのプロバイダー固有のクラスが含まれます。詳細については、
データ プロバイダー固有のクラスを参照してください。共通プログラミング モデルを使用する場合は、Zen Common Assembly のクラスを使用できます(
Zen Common Assembly を参照してください)。
Pervasive.Data.Common アセンブリには、バルク データ形式間の機能を提供する CsvDataReader および CsvDataWriter などの Zen Bulk Load に対応したクラスが含まれています。
共通アセンブリは、共通プログラミング モデルを使用するバルク ロード クラスのサポート機能も拡張します。つまり、SqlBulkCopy パターンが新しい DbBulkCopy 階層で使用できるようになりました。
データ プロバイダーの将来のバージョンには、共通プログラミング モデル技術を拡張するほかの機能が含められます。Pervasive.Data.Common アセンブリが対応しているクラスの詳細については、
Zen Common Assembly を参照してください。
バルク ロード データ ファイル
異なるデータ ストア間でのクエリの結果は、カンマ区切り値(CSV)形式ファイルであるバルク ロード データ ファイルに保存されます。BulkFile プロパティで定義されるファイル名は、バルク データの読み書きに使用されます。ファイル名に拡張子が含まれない場合は、".CSV" と見なされます。
例
Zen ソース テーブルの GBMAXTABLE には 4 つの列が含まれています。次の C# コード例は、CsvDataWriter によって作成される GBMAXTABLE.csv および GBMAXTABLE.xml への書き出しを行います。この例では、DbDataReader クラスを使用していることに注目してください。
cmd.CommandText = "SELECT * FROM GBMAXTABLE ORDER BY INTEGERCOL";
DbDataReader reader = cmd.ExecuteReader();
CsvDataWriter csvWriter = new CsvDataWriter();
csvWriter.WriteToFile("\\NC1\net\Zen\GBMAXTABLE\GBMAXTABLE.csv", reader);
バルク ロード データ ファイルの GBMAXTABLE.csv には、次のようなクエリの結果が含まれます。
1,0x6263,"bc","bc"
2,0x636465,"cde","cde"
3,0x64656667,"defg","defg"
4,0x6566676869,"efghi","efghi"
5,0x666768696a6b,"fghijk","fghijk"
6,0x6768696a6b6c6d,"ghijklm","ghijklm"
7,0x68696a6b6c6d6e6f,"hijklmno","hijklmno"
8,0x696a6b6c6d6e6f7071,"ijklmnopq","ijklmnopq"
9,0x6a6b6c6d6e6f70717273,"jklmnopqrs","jklmnopqrs"
10,0x6b,"k","k"
GBMAXTABLE.xml ファイルは、このバルク ロード データ ファイルの形式を指定するバルク ロードの設定ファイルです。これについて次のセクションで説明します。
バルク ロード構成ファイル
バルク ロード構成ファイルは、CsvDataWriter.WriteToFile メソッドが呼び出されたときに作成されます(詳細については
CsvDataWriter を参照してください)。
バルク ロード構成ファイルは、バルク ロード データ ファイル内の列の名前とデータ型を定義します。これらの名前とデータ型は、データのエクスポート元のテーブルや結果セットと同様に定義します。
バルク データ ファイルが作成できなかったり XML 構成ファイルに記述されているスキーマに準拠していない場合は、例外がスローされます。XML スキーマ定義の使用法については、
バルク データ構成ファイル用の XML スキーマ定義を参照してください。
構成ファイルを持たないバルク ロード データ ファイルが読み込まれた場合は、以下のデフォルトが想定されます。
•すべてのデータは文字データとして読み取られます。カンマの間にある値は、それぞれ文字データとして読み取られます。
•デフォルトの文字セットは、バルク ロード CSV ファイルが現在読み取られているプラットフォームの文字セットです。詳細については、
文字セットの変換を参照してください。
バルク ロード設定ファイルは、バルク データ ファイルについて記述されており、基となる XML スキーマによってサポートされます。XML スキーマについては次で定義されています。
例
前のセクションで示したバルク ロード データ ファイルは、バルク ロード構成ファイルの GBMAXTABLE.xml で定義されています。このファイルには、テーブル内の 4 つの列のそれぞれについてデータ型とその他の情報が記述されています。
<?xml version="1.0" encoding="utf-8"?>
<table codepage="UTF-16LE" xsi:noNamespaceSchemaLocation="http://www.datadirect.com/ns/bulk/BulkData.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<row>
<column datatype="DECIMAL" precision="38" scale="0" nullable=
"false">INTEGERCOL</column>
<column datatype="VARBINARY" length="10" nullable=
"true">VARBINCOL</column>
<column datatype="VARCHAR" length="10" sourcecodepage="Windows-1252"
externalfilecodepage="Windows-1252" nullable="true">VCHARCOL</column>
<column datatype="VARCHAR" length="10" sourcecodepage="Windows-1252"
externalfilecodepage="Windows-1252" nullable="true">UNIVCHARCOL</column>
</row>
</table>
バルク ロード プロトコルの決定
バルク操作は、専用のバルク プロトコルを使用して実行できます。つまり、データ プロバイダーは基となるデータベースのプロトコルを使用します。場合によっては、専用のバルク プロトコルが使用できない場合があります。たとえば、ロードしようとするデータが、専用のバルク プロトコルが対応していないデータ型の場合です。その場合、データ プロバイダーは配列バインドなどの非バルク手法を自動的に使用してバルク操作を実行し、最適なアプリケーション稼働時間を継続します。
文字セットの変換
時には、異なる文字セットを使用するデータベース間でデータをバルク ロードする必要があります。
Control Center では、デフォルトのソース文字データ、つまり CsvDataReader からの出力および CsvDataWriter への入力は Unicode(UTF-16)形式です。ソース文字データは、常に CSV ファイルのコード ページに変換されます。しきい値を超えてデータが外部のオーバーフロー ファイルに書き出された場合、ソース文字データはバルク構成 XML スキーマで定義されている externalfilecodepage 属性で指定されたコード ページに変換されます(
バルク データ構成ファイル用の XML スキーマ定義を参照してください)。構成ファイルで externalfilecodepage の値が定義されていない場合は CSV ファイルのコード ページが使用されます。
不要な変換処理を行わないためには、CSV および外部ファイルの文字データを Unicode(UTF-16)にするのが最良の方法です。以下のいずれかの状況では、アプリケーションにデータを別のコード ページで保存させたい場合があります。
•データが ADO.NET で書き出され ODBC で読み取られる。この場合、読み取り(および関連する文字変換)は ODBC によって行われます。文字データが既に正しいコード ページである場合、文字変換は不要です。
•空白が考慮の対象となる。文字データがよりコンパクトに表されるかどうかは、コード ページによって異なります。たとえば、ASCII データは 1 文字が 1 バイトで、UTF-16 は 1 文字が 2 バイトです。
構成ファイルでは、任意で文字型の列ごとに 2 番目のコード ページを定義することができます。文字データが CharacterThreshold プロパティで定義した値を超え、別個のファイルに格納される場合(
外部オーバーフロー ファイルを参照してください)、この値はそのファイルのコード ページを定義します。
この値を省略したりソース列で定義されたコード ページが不明の場合は、CSV ファイルに定義されたコード ページが使用されます。
外部オーバーフロー ファイル
CsvDataWriter オブジェクトの BinaryThreshold または CharacterThreshold プロパティの値がしきい値を超えた場合、別のファイルが生成されてバイナリまたは文字データを格納します。これらのオーバーフロー ファイルは、バルク データ ファイルと同じディレクトリにあります。
オーバーフロー ファイルに文字データが含まれる場合、ファイルの文字セットは CSV バルク構成ファイルで指定された文字セットが決定します。
ファイル名には CSV ファイル名と拡張子 ".lob" が含まれます(たとえば、CSV_filename_nnnnnn.lob)。これらのファイルは CSV ファイルと同じ場所に存在します。_000001.lob から開始して 1 ずつ大きくなります。
バルク コピー操作とトランザクション
デフォルトで、バルク コピー操作はトランザクションの一部ではなく分離した操作として実行されます。つまり、エラーが発生しても操作をロール バックするチャンスはないということです。
Zen では、既存のトランザクション内でバルク コピー操作を行うことができます。複数の手順で存在するトランザクションの一部としてバルク コピー操作を定義することができます。この手法を使うと、複数のバルク コピー操作を同じトランザクション内で実行し、トランザクション全体をコミットまたはロール バックすることができます。
エラー発生時にバルク コピー操作のすべてまたは一部をロール バックする方法については、Microsoft のオンライン ヘルプで "トランザクションとバルク コピー操作(ADO.NET)" を参照してください。
診断機能の使用
.NET Framework では、プログラムを再コンパイルすることなくエンド ユーザーが問題を特定するのに役立つ Trace クラスを提供します。
Control Centerはさらに以下の診断機能を実現します。
•メソッド呼び出しのトレース機能
•アプリケーションの接続情報の監視を可能にする、パフォーマンス モニターのフック
メソッド呼び出しのトレース
トレース機能は、環境変数または PsqlTrace クラスを使って有効にできます。データ プロバイダーは、パブリック メソッドの全呼び出しの入力引数と、そのメソッドの出力および戻り値(ユーザーが呼び出したものすべて)をトレースします。各呼び出しには、メソッドの開始(ENTER)と終了(EXIT)のエントリがあります。
デバッグ中、機密事項のデータがプライベート変数または内部変数として格納され、アクセスが同じアセンブリに制限されたとしても、そのデータを読み取ることができます。セキュリティを維持するために、トレース ログはパスワードを 5 つのアスタリスク(*****)で示します。
環境変数の使用
環境変数を使用してトレースを有効にするということは、アプリケーションを変更しなくてもよいということです。ただし、環境変数の値を変更したら、その新しい値を有効にするにはアプリケーションの再起動が必要になります。
表
3 では、トレースを有効にしたり制御したりするための環境変数について説明します。
表 3 環境変数
環境変数 | 説明 |
|---|
PVSW_NET_Enable_Trace | 1 以上に設定すると、トレースが有効になります。0(デフォルト)に設定すると、トレースは無効になります。 |
PVSW_NET_Recreate_Trace | 1 に設定すると、アプリケーションを開始するたびにトレース ファイルが再作成されます。0(デフォルト値)に設定すると、トレース ファイルに追加されます。 |
PVSW_NET_Trace_File | トレース ファイルのパスと名前を指定します。 |
注記
•PVSW_NET_Enable_Trace = 1 に設定すると、トレース処理が開始されます。そのため、トレースを有効にする前に、トレース ファイルのプロパティ値を定義しておく必要があります。いったんトレース処理が開始されたら、ほかの環境変数の値を変更することはできません。
•接続文字列オプションでも環境変数でもトレース ファイルが指定されていないのにトレースを有効にすると、データ プロバイダーは PVSW_NETTrace.txt という名前のファイルに結果を保存します。
静的メソッドの使用
ユーザーによっては、トレースを有効にするのに、データ プロバイダーの Trace クラスの静的メソッドを使用する方が便利だと思われるかもしれません。以下の C# コードでは、.NET Trace オブジェクトの静的メソッドを使用して、トレース ファイルの名前を MyTrace.txt とする PsqlTrace クラスを作成します。この値は環境変数で設定した値よりも優先されます。これ以降、データ プロバイダーへの呼び出しはすべて MyTrace.txt へトレースされます。
PsqlTrace.TraceFile="C:\\MyTrace.txt";
PsqlTrace.RecreateTrace = 1;
PsqlTrace.EnableTrace = 1;
トレースは次のような形式で出力されます。
<Correlation#> <Timestamp> <CurrentThreadName>
<Object Address> <ObjectName.MethodName> ENTER (または EXIT)
Argument #1 : <Argument#1 Value>
Argument #2 : <Argument#2 Value>
...
RETURN: <Method ReturnValue> // EXIT の場合のみ
各項目の説明は次のとおりです。
Correlation# は重複のない番号で、これによって、アプリケーション内の同じメソッド呼び出しの ENTER エントリと EXIT エントリを符合させます。
Value は、個々の関数呼び出しに固有のオブジェクトのハッシュ コードです。
デバッグ中、機密事項のデータがプライベート変数または内部変数として格納され、アクセスが同じアセンブリに制限されたとしても、そのデータを読み取ることができます。セキュリティを維持するために、トレース ログはパスワードを 5 つのアスタリスク(*****)で示します。
PerfMon のサポート
パフォーマンス モニター(PerfMon)や VS パフォーマンス モニター(VSPerfMon)ユーティリティを使用すると、アプリケーションのパラメーターを記録し、その結果をレポートやグラフにして見ることができます。また、パフォーマンス モニターではアプリケーションの CLR(共通言語ランタイム)例外の回数や頻度を確認することもできます。加えて、使用中の接続数や接続プール数を分析して、ネットワークの負荷を調整することができます。
データ プロバイダーは、このデータ プロバイダーを使用するアプリケーションの調整およびデバッグが行える PerfMon カウンターのセットをインストールします。カウンターは、パフォーマンス モニターの[Zen ADO.NET Data Provider]というカテゴリ名の下に置かれます。
表
4 では、アプリケーションの接続を調整するために使用できる各種 PerfMon カウンターについて説明します。
表 4 PerfMon カウンター
カウンター | 説明 |
|---|
Current # of Connection Pools | プロセスに関連付けられている現在のプール数。 |
Current # of Pooled and Non-Pooled Connections | プールされている接続とプールされていない接続の現在の数。 |
Current # of Pooled Connections | プロセスに関連付けられているすべてのプールにある現在の接続数。 |
Peak # of Pooled Connections | プロセスの開始後、すべての接続プールにおいてカウントされた最大の接続数。 |
Total # of Failed Commands | プロセスの開始後、何らかの理由でエラーになったコマンドの実行総数。 |
Total # of Failed Connects | プロセスの開始後、何らかの理由でエラーになった接続を開くために試行した合計回数。 |
PerfMon とパフォーマンス カウンターの使用法の詳細については、Microsoft ドキュメント ライブラリを参照してください。
接続統計情報によるパフォーマンスの分析
.NET Framework 2.0 以上では実行時の統計をサポートしており、統計情報は接続単位で収集されます。Control Centerは、幅広い種類の実行時の統計情報項目をサポートしています。これらの統計情報項目が提供する情報は、以下に役立ちます。
•アプリケーション パフォーマンスの自動分析
•アプリケーション パフォーマンスの傾向の特定
•接続での問題の検出および通知の送信
•データ接続での問題修正の優先順位決定
統計情報項目の計測がパフォーマンスに与える影響はわずかです。最良の結果を得るためには、ネットワーク分析またはアプリケーションのパフォーマンス作用分析時にのみ統計情報の収集を有効にすることを考慮してください。
統計情報収集は、すべての Connection オブジェクトで、それらが使用可能である限り有効にできます。たとえば、アプリケーションで、ビジネス分析の実行に関連する複雑なトランザクションのセットを開始する前に統計情報を有効にし、タスクの完了時に統計情報を無効にするように定義できます。データ プロバイダーがサーバーに対して待機させられた時間および返された行数をタスクの完了直後に取得できますし、後から取得することもできます。アプリケーションはタスクの最後で統計情報を無効にするため、統計情報項目は関心のある期間だけ計測されます。
統計情報項目は、機能上 4 つのカテゴリに分類されます。
•ネットワーク レイヤ項目は、送受信されるバイト数およびパケット数、データ プロバイダーがサーバーの応答を待った時間などのネットワーク動作に関連する値を取得します。
•集計項目は、サーバーとのやりとりごとに送受信されたバイト数などの計算値を返します。
•行処理の統計情報項目は、アプリケーションが読み取らなかった行の処理に必要な時間とリソースに関する情報を提供します。
•ステートメント キャッシュの統計情報項目は、ステートメント キャッシュ内でのステートメントの動作を説明する値を返します(ステートメント キャッシュの使用法については、
ステートメント キャッシングの使用を参照してください)。
統計情報項目の有効化と取得
Connection オブジェクトを作成すると、StatisticsEnabled プロパティを使用して統計情報の収集を有効にすることができます。データ プロバイダーは、接続が開かれると統計情報項目のカウントを開始し、ResetStatistics が呼び出されるまで継続します。接続を閉じた後 ResetStatistics を呼び出さずに再度開くと、統計情報項目のカウントは接続が閉じられた時点から継続されます。
RetrieveStatistics メソッドを呼び出すと、1 つまたは複数の統計情報項目のカウントを取得します。返される値は、RetrieveStatistics メソッドが呼び出された時点での "適切な時期のスナップショット" となります。
統計情報収集および取得の範囲を定義できます。次の C# コード例では、統計情報項目はタスク A 作業のみを測定し、タスク B 作業の処理後に回収されます。
connection.StatisticsEnabled = true;
// タスク A 作業を行います
connection.StatisticsEnabled = false;
// タスク B 作業を行います
IDictionary currentStatistics = connection.RetrieveStatistics();
すべての統計情報項目を表示するには、次の C# コード例のようなコードを使用することができます。
foreach (DictionaryEntry entry in currentStatistics) {
Console.WriteLine(entry.Key.ToString() + ": " + entry.Value.ToString());
}
Console.WriteLine();
SocketReads および SocketWrites 統計情報項目のみを表示するには、次の C# コード例のようなコードを使用できます。
foreach (DictionaryEntry entry in currentStatistics) {
Console.WriteLine("SocketReads = {0}",
currentStatistics["SocketReads"]);
Console.WriteLine("SocketWrites = {0}",
currentStatistics["SocketWrites"]);
}
Console.WriteLine();
ADO.NET Entity Framework ユーザーへの注記:PsqlConnection の統計情報用のメソッドおよびプロパティは、ADO.NET Entity Framework レイヤーでは利用できません。代わりに、データ プロバイダーは「擬似」ストアド プロシージャを介して同様の機能を公開します。詳細については、
ADO.NET Entity Framework でのストアド プロシージャの使用を参照してください。