Maintenance を使用した Btrieve データ ファイルの操作
Maintenance ツールを使用した Btrieve データ ファイルの操作
この章では、以下の項目について説明します。
Maintenance ユーティリティの概要
Zen には、対話型の Maintenance GUI おびコマンド ラインの Maintenance ツールが用意されています。どちらのバージョンも以下のファイル操作およびデータ操作を行います。
•定義したファイルおよびキー仕様に基づいた新規データ ファイルの作成
•既存データ ファイルのファイルおよびキー仕様の設定
•データ ファイルのオーナー ネームの設定とクリア
•データ ファイルのインデックスの作成と削除
•ASCII シーケンシャル データのインポートとエクスポート
•Zen データ ファイル間のデータのコピー
•最後のバックアップからシステム エラーが発生する間に行ったファイルへの変更の回復
2 つのユーティリティは基本的に同じですが、機能が異なる部分が多少あります。たとえば、対話型 Maintenance ツールでは、定義したファイルおよびキー仕様に基づいてディスクリプション ファイルを作成することができますが、コマンド ライン Maintenance ツールでは、サーバー上でファイルの Continuous オペレーションを直接開始または停止することができます。
Maintenance ツールを使用する前に、ファイル、レコード、キー、セグメントなどの Btrieve の基本概念について熟知しておく必要があります。これらのトピックスの詳細については、『Zen Programmer's Guide』を参照してください。
メモ:Zen 製品では次の 2 種類の Maintenance ツールを提供します。Btrieve および SQL の 2 つです。SQL Maintenance ツールは ODBC 経由でのリレーショナル アクセスに使用するデータ ソース名(DSN)をサポートします。
対話型 Maintenance ツール
対話型 Maintenance ツールは、Windows 32 ビットおよび 64 ビット プラットフォームで実行される Windows アプリケーションです。このツールは、グラフィカル インターフユーザェイスを使用した場合、またはディスクリプション ファイルを作成したい場合に使用します。このセクションには次の主なトピックがあります。
それぞれの主なトピックにはそのトピックに固有のタスクがあります。
拡張ファイルのサポート
MicroKernel データ ファイルは、オペレーティング システムのファイル サイズ上限を超えた容量を持つことが可能です。データを、MicroKernel の拡張ファイルからシーケンシャル ファイルにエクスポートした際、実際の形式の違いから、そのシーケンシャル ファイルの容量がデータベース エンジンのファイル サイズ上限を超える場合があります。
大きなサイズのファイルをエクスポートする際、対話型 Maintenance ツールでは、シーケンシャル ファイルがファイル サイズの上限(2 GB)を超えていることを検出すると、エクステンション ファイルの作成が開始されます。この処理は自動的に行われます。エクステンション ファイルおよび元のシーケンシャル ファイルは、同じボリューム内に存在する必要がありますファイルのサイズの制限は、オペレーティング システムやファイル システムによって異なるので注意してください。2 GB というサイズはデータベース エンジンでサポートされる制限サイズです。
エクステンション ファイルの名前には、ベース ファイルと似た名前を付ける方式が使用されます。エクステンション ファイルを示すのに、ネイティブな MicroKernel エンジン エクステンション ファイルがキャレット("^")を使用するのに対し、シーケンシャル ファイルのエクステンション ファイルはチルダ("~")を使用するので、同じベース ファイル名を持つ既存のエンジン拡張ファイルを上書きするのを防ぎます。最初のエクスポート エクステンション ファイルには、ベース ファイル名に ".~01" という拡張子が付きます。次のエクステンション ファイルには、ベース ファイル名に ".~02" というように拡張子が付けられます。これらの拡張子は 16 進形式で追加されます。
名前付け規則は 255 までのエクステンション ファイルをサポートします。したがって、最大ファイル サイズは 256 GB です。
また、シーケンシャル ファイルからデータをインポートする場合は、ファイルが拡張されているかどうかがチェックされ、エクステンション ファイルからデータがロードされます。
長いファイル名と埋め込みスペースのサポート
スペースを含む長いファイル名は、サポートされるすべてのオペレーティング システムで使用できます。参照対象となるすべてのファイル名には、埋め込みスペースを含むことが可能であり、また 8 バイトを超える名前も使用可能です。
Btrieve の古いバージョンでは、Open や Create など、パスに基づくオペレーションの際に、ファイル名の最後にスペースを追加することができました。このバージョンでも、デフォルトとしてこれが設定されており、操作に支障をきたしませんが、バージョン埋め込みスペースを含むファイル名やディレクトリ名も正しく認識する機能を利用したい場合は、クライアント リクエスターの[スペースを含むファイル/ディレクトリ名]設定をオンに設定します。デフォルトの設定はオンです。
このオプションをオフに設定した場合でも、埋め込みスペースを含む名前を持つファイルにアクセスする際に、アプリケーションがファイルを開く、または作成する BTRV/BTRVID/BTRCALL/BTRCALLID コールを行うとき、その名前を二重引用符で囲めば、使用することができます。
レコードおよびページ圧縮
Zen ではレコードおよびページによる 2 種類のデータ圧縮を提供します。これら 2 種類のデータ圧縮は、別々に使われることもあれば、一緒に使われることもあります。2 つの圧縮タイプの主な目的はいずれも、データ ファイルのサイズを減らし、データのタイプとデータ操作のタイプに応じてより速いパフォーマンスを提供することです。
レコード圧縮
レコード圧縮には 6.0 以上のファイル形式が必要です。レコード圧縮により、多数の繰り返し文字を含むレコードの格納に必要なスペースを大幅に削減できます。データベース エンジンは、5 つ以上連続する同一文字を 3 バイトに圧縮します。
ファイルの作成時、指定されたレコード長に余裕を持たせるため、データベース エンジンは自動的に指定されたより大きいページ サイズを使用します。圧縮されていないレコードが、使用できる最大ページに収まりきらないほど大きい場合、データベース エンジンは自動的にレコード圧縮をオンにします。
圧縮レコードの最終的な長さは、ファイルに書き込まれるまで決定されないため、データベース エンジンはレコード圧縮されたファイルを可変長レコード ファイルとして作成します。レコードの圧縮されたイメージは可変長レコードとして格納されます。アプリケーションがレコードの追加、更新、削除を頻繁に行うと、個々のレコードはいくつかのファイル ページに断片化されます。データベース エンジンは 1 つのレコードを取得するために複数のファイル ページを読み取らなければならない場合があるので、この断片化によってアクセス時間が遅くなるおそれがあります。
『
Zen Programmer's Guide』の
ページ サイズの選択、
ファイル サイズの予測および
レコード圧縮を参照してください。
ページ圧縮
ページ圧縮には 9.5 以上のファイル形式が必要です。内部的には、Zen データ ファイルはさまざまな種類のページの連続です。ページ圧縮は、ファイル内のデータ ページの圧縮と復元を制御します。
ファイルが物理ストレージから読み取られると、データ ページは復元されてメモリ キャッシュに保持されます。レコードの読み取りと更新は、メモリ キャッシュ内の圧縮されていないデータに対して行われます。書き込み操作が行われると、データ ページは圧縮されて物理ストレージに書き込まれます。圧縮されたページが、次回アクセスされるまで保持されるかどうかは、キャッシュ管理によって異なります。
データの種類によって圧縮しても意味がない場合、データベース エンジンはそのデータを圧縮しないで物理ストレージに書き込みます。
圧縮の使用時期の判断
レコード圧縮、ページ圧縮、あるいはその両方を使用することで得られる利点は、圧縮されるデータのタイプによって異なります。次の表では、データ圧縮を使用するかどうかを判断するための一般的な要因を説明します。
表 67 データ圧縮がふさわしいか考慮するための要因
圧縮 | 考慮する要因 |
|---|
レコード | ページ |
|---|
| | レコード圧縮は、以下の条件の場合に最も効果的です。 •各レコードに文字の繰り返しが多数含まれる可能性がある。たとえば、レコードにいくつかのフィールドが含まれており、レコードをファイルに挿入するときにそれらのフィールドはすべてタスクによって空白に初期化される可能性があります。レコード圧縮は、これらのフィールドがほかの値を含むフィールドで分割される場合でなく、レコード内で 1 つにグループ化される場合に有効です。 •データベース エンジンを実行するコンピューターが、圧縮バッファーで必要となる追加メモリを提供できる。 •レコードは、変更されることに比べ、より頻繁に読み取られる。 レコードの固定長部分が「ページ サイズ - オーバーヘッド」より長い場合、自動的に圧縮が使用されます。 レコード圧縮は、キー オンリー ファイルやブランク トランケーションを使用するファイルには使用できません。 |
| | ページ圧縮は、以下の条件の場合に最も効果的です。 •データが ZIP タイプの圧縮アルゴリズムを使用して高度に圧縮可能である。ページ圧縮によってファイル サイズが 1/4 程度に著しく縮小できる場合、ファイルのパフォーマンスはかなり向上します。 •ページは、追加、更新、削除されることに比べ、より頻繁に読み取られる。 圧縮しても意味がない場合、データベース エンジンはデータ ページを圧縮しないで物理ストレージに書き込みます。 |
| | レコード圧縮およびページ圧縮の使用は、レコードに大きな空白部分が含まれる場合と、ページが追加、更新、削除されることに比べ頻繁に読み取られる場合に最も効果的です。 |
Maintenance ツールのインターフェイス
オペレーティング システムの[スタート]メニューまたはアプリ画面から、あるいは Zen Control Center の[ツール]メニューから Maintenance ユーティリティにアクセスします。Maintenance ユーティリティのメイン ウィンドウは次のようになっています。
図 18 Maintenance ツールのメイン ウィンドウ
メニュー オプション
対話型 Maintenance ツールには、以下のメニューが用意されています。
オプション | ファイル情報エディターの表示、オーナー ネームの設定およびクリア、ファイル情報レポートの生成、ツールの終了を行います。 |
インデックス | インデックスの作成と削除を行います。 |
データ | ASCII ファイルからのデータのロード、ASCII ファイルへのデータの保存、データ ファイル間のレコードのコピー、および最後のバックアップからシステム エラーが発生するまでの間に行ったデータ ファイルへの変更を回復するためのロール フォワードを行います。 |
ヘルプ | Maintenance ツールのヘルプを起動します。 |
ヘルプの起動
Maintenance ツールのヘルプを使用するには、ヘルプの必要なダイアログ ボックスで[ヘルプ]をクリックするか、以下のような[ヘルプ]メニューのコマンドを選択します。
ヘルプの起動 | Maintenance ツールのヘルプ トピックが表示されます。 |
バージョン情報 | 著作権情報および製品のバージョン番号が表示されます。 |
ファイル情報エディター
このセクションでは、構築するファイルおよびキー仕様に基づいて新しいファイルを作成する[ファイル情報エディター]に関する一般的な説明を行います。このエディターでは、既存ファイルの情報をロードできるため、既存データ ファイルのファイル仕様やキー仕様の確認に便利です。また、既存ファイルのファイル仕様やキー仕様に基づいた新規ファイルの作成も可能です(コマンド ライン Maintenance ツールである butil の clone コマンドと同様)。
注意: 同じディレクトリに、ファイル名が同一で拡張子のみが異なるようなファイルを置かないでください。たとえば、同じディレクトリ内のデータ ファイルの 1 つに Invoice.btr、もう 1 つに Invoice.mkd という名前を付けてはいけません。このような制限が設けられているのは、データベース エンジンがさまざまな機能でファイル名のみを使用し、ファイルの拡張子を無視するためです。ファイルの識別にはファイル名のみが使用されるため、ファイルの拡張子だけが異なるファイルは、データベース エンジンでは同一のものであると認識されます。
ファイル情報エディターを開くには、[オプション]>[情報エディターの表示]をクリックします。
図 19 ファイル情報エディター
[ファイル情報エディター]ダイアログの項目
エディターの上部には、以下のボタンが表示されます。
情報のロード | 既存ファイルの情報をロードします。ファイル情報をロードしても、ファイルが編集されることはありません。既存ファイルに関する情報のコピーのみがロードされます。 |
ファイルの作成 | ダイアログ ボックスの現在の情報に基づいて新規ファイルを作成します。 |
デフォルトに設定 | 設定をデフォルト値に戻します。 |
ディスクリプション コメント | ディスクリプション ファイルを作成する場合は、ファイルに関するメモを入力することができます。 |
ヘルプ | [ファイル情報エディター]ダイアログ ボックスのヘルプを表示します。 |
データ ファイル情報
[ファイル情報エディター]の上部の[データ ファイル情報]領域には、以下のコントロールが含まれます。
オーナー ネーム | ファイルのオーナー ネームが存在する場合は、アスタリスク文字列として表示されます。 |
バージョン | ファイルの全属性を読み取ることができるデータベース エンジンの最も古いバージョンを表します。たとえば、バージョン 9.5 の データベース エンジンでファイルを作成したが、バージョン 9.5 特有の属性を使用しなかった場合、Maintenance ツールでは、バージョン 9.0 と表示されます。ファイル形式のバージョンについては ファイル バージョンに関する注意を参照してください。 |
総レコード数 | ファイルのレコード総数を表します。 |
ファイル仕様
[ファイル情報エディター]の中央部に[
ファイル仕様]領域があります。表
68 はこのボックス内のコントロールの説明です。
表 68 [ファイル仕様]のコントロール
コントロール | 説明 | 範囲 | デフォルト |
|---|
レコード長 | ファイルの固定長レコードの論理データ レコード長(バイト単位)を設定します。 レコード長およびオーバーヘッドの説明については、『Zen Programmer's Guide』の「レコード長」セクションを参照してください。 | 最低 4 バイト。最大値はファイル バージョンによって異なります。指定されたレコード長が、ページ サイズからオーバヘッドを差し引いた数値を超える場合、データベース エンジンは自動的にそのファイル形式で次に使用可能なページ サイズになるよう試行します。レコード長が、最大ページ サイズからオーバーヘッドを差し引いた数値を超える場合、エンジンはレコードの圧縮をオンにします。 | 100 |
ページ サイズ | ファイルの物理ページ サイズ(バイト単位)を設定します。 | 512 - 4096:9.0 より前のファイル バージョンの場合(512 バイトの倍数で最大 4096 バイト) 512、1024、1536、2048、2560、3072、3584、4096 または 8192:ファイル バージョンが 9.0 の場合 1024、2048、4096、8192 または 16384:ファイル バージョンが 9.5 の場合 4096、8192 または 16384:ファイル バージョンが 13.0 の場合 | 4096 |
キー数 | (キー セグメントと対照して)エディターで現在定義されている識別キーの数を表します。キー リストのキーの数が反映されます。 | 0 – 119 | 0 |
セグメント数 | エディターで現在定義されているキー セグメントの数を表します。セグメント リストのセグメントの数が反映されます。 | 0 - 119:9.5 より前のファイル バージョンの場合。 0 - 420:ファイル バージョン 9.5 の場合。 0 - 378:ファイル バージョン 13.0 の場合。 | 0 |
リンク可能キー | 将来のリンク重複キーに予約する 8 バイト プレースホルダーの数を設定します。既存データ ファイルの情報をロードしている場合、そのファイルで現在使用可能なプレースホルダーの数がこの数値に反映されます。元から予約してあるプレースホルダーの数は、ファイルに保存されません。 | 0 – 119 | 3 |
キーオンリー | ファイルがキー オンリーかどうかを表します。レコードタ圧縮または可変長レコードを有効にした場合、およびファイルに複数のキーを定義した場合は、この設定は使用できません。 | オンまたはオフ | オフ |
インデックス バランス | ファイルにおけるキー ページ管理のインデックス バランスの使用を設定します。 | オンまたはオフ | オフ |
プリアロケーション | ファイルにおけるプリアロケート ページの使用を設定します。 | オンまたはオフ | オフ |
ページ数 | ファイル作成時にプリアロケートするページの数を設定します。[プリアロケーション]がオンの場合にのみ設定できます。既存データ ファイルの情報をロードしている場合、そのファイルの未使用の残りプリアロケート ページ数がこの数値に反映されます。元からプリアロケートしてあるページの数は、ファイルに保存されません。 | 1 – 65535 | 0 |
レコード圧縮 | ファイルにおけるレコード圧縮の使用を設定します。キー オンリー ファイル、またはブランク トランケーションを使用するファイルには対応していません。 レコードおよびページ圧縮も参照してください。 | オンまたはオフ | オフ |
ページ圧縮 | ファイルにおけるページ圧縮の使用を設定します。 レコードおよびページ圧縮も参照してください。 | オンまたはオフ | オフ |
可変長レコード | ファイルに、可変長レコードを含むことができるかどうかを設定します。 | オンまたはオフ | オフ |
ブランク トランケーション | ディスク領域を確保するために、ファイルが可変長レコードに対してブランク トランケーションを使用するかどうかを設定します。この設定は、可変長レコード有効時のみ可能です。 | オンまたはオフ | オフ |
VAT | ファイルが、長いレコード内のデータへ高速にアクセスするため、可変長部割り当てテーブルを使用するかどうかを設定します。この設定は、可変長レコード有効時のみ可能です。 | オンまたはオフ | オフ |
% 空きスペース | 新規可変ページ作成前に、ファイルの可変ページが確保する未使用スペースの量を設定します。この設定は、[レコード圧縮]または[可変長レコード]がオンの場合にのみ設定できます。 | 5、10、20、30 | 5 |
キー
ダイアログ ボックスの左下部には[
キー]グループ ボックスがあります。表
69 はこの領域のコントロールの説明です。これらのコントロールは、現在のキー セグメントだけでなく、[
キー]リストで選択されているキーに固有です。これらの設定を変更した場合、指定したキーの
すべてのセグメントに対して変更が適用されます。
表 69 [キー]のコントロール
コントロール | 説明 | デフォルト |
|---|
重複可能 | キーが、重複する値(リンク重複)を持つことができるかどうかを設定します。 | オン |
変更可能 | キーの値を、作成後に変更できるかどうかを設定します。キー値の変更を許可してもパフォーマンスには影響しません。キー ページは、実際のキー値が変更された場合にのみ更新され、特定のレコードのキー以外のフィールドが変更されても更新されません。 | オン |
繰り返し重複 | 重複キー値を格納するのにデータベース エンジンがくり返し重複の手法を使用するよう指定します。 | オフ |
散布キー(ヌル キー) | 散布キーには、ファイル内にあるレコード数よりも少ない数のキー値が含まれます。インデックスから除外するキー値を指定するには、この次にある 2 つのコントロールを参照してください。この設定は、ヌル可能なセグメントが含まれるキーの場合のみ可能です。 | オフ |
全セグメント(ヌル) | レコードのすべてのキー セグメントにヌル値が含まれる場合に、そのレコードをインデックスに含まれないよう設定します。この設定は、散布キー(ヌル キー)有効時のみ可能です。キー フラグ 0x0008 に相当します。セグメントがヌルとして評価されるかどうかは、そのフィールドのヌル インジケーター セグメントだけを基に判断されます。そのフィールドの内容は評価されません。 | オフ |
一部セグメント(マニュアル) | 1 つまたは複数のキー セグメントにヌル値が含まれる場合に、そのレコードをインデックスに含めないよう指定します。この設定は、散布キー(ヌル キー)有効時のみ可能です。キー フラグ 0x0200 に相当します。セグメントがヌルとして評価されるかどうかは、そのフィールドのヌル インジケーター セグメントだけを基に判断されます。そのフィールドの内容は評価されません。 | オフ |
ACS 情報 | キーのオルタネート コレーティング シーケンス(ACS)を設定します。この設定は、キーのセグメントに対する[ACS を使用する]チェック ボックスがオンの場合にのみ使用できます。 | オフ |
ユニーク値 | ファイルにある重複しないキー値の数を表します。これは、既存データ ファイルの情報をロードしている場合のみ表示されます。 | 適用外 |
[キー]リストおよび[セグメント]リスト
ダイアログ ボックス中央下部の[キー]リストには、ファイルに定義されているキー番号が表示されます。バージョン 6.x 以降のファイルでは、このキー番号が連続した数値である必要はありません。Maintenance ツールでは、選択されたキーの仕様が、ダイアログ ボックス左下部の[キー]ボックスに表示されます。
また、ダイアログ ボックス中央下部の[セグメント]リストには、[キー]リストで選択されたキーに定義されている、キー セグメント番号が表示されます。Maintenance ツールでは、選択されたセグメントの仕様が、ダイアログ ボックス右下部の[セグメント]ボックスに表示されます。
また、[キー]と[セグメント]リストには、以下のボタンが表示されます。
挿入 | 新しいキーまたはセグメントを定義します。 |
削除 | 選択されたキーまたはセグメントの仕様を削除します。 |
圧縮 | キーの番号を再割り当てします。このボタンは、キー仕様を削除することによって生じたキー番号の不連続をなくすことができます。 |
これらのボタンは、作成するファイルのキー仕様を設定するもので、既存ファイルのキーに対して使用することはできません。既存ファイルのインデックスを作成または削除する場合は、
インデックスの作業を参照してください。
キー セグメント
ダイアログ ボックスの右下部には[
キー セグメント]グループ ボックスがあります。表
70 はこの領域のコントロールの説明です。これらのコントロールは、[
セグメント]リストで選択されているセグメントに固有のものです。
表 70 [キー セグメント]グループ ボックスのコントロール
コントロール | 説明 | デフォルト |
|---|
データ型 | キー セグメントのデータ型を指定します。 NULL データ型は、インデックスが 1 バイトのヌル インジケーター セグメントであることを示します。このセグメントはマルチ セグメント キー内にあり、NULL 型でないほかのキー セグメントの前にある必要があります。このキー タイプに使用される Btrieve API の番号は 255 です。 | String |
位置 | レコード内でのこのキー セグメントの相対的な開始位置を、数値で設定します。この数値は、レコード長を超えて設定することはできません。 | 1 |
長さ | キー セグメントの長さ(バイト単位)を設定します。この数値は、セグメントのデータ型に指定された制限を超えることはできません。キー位置とキー長の合計も、レコード長を超えないように注意してください。 | 10 |
ヌル値(16 進) | キー セグメントのヌル文字値(16 進数)を設定します。この設定は、キーに対する[ヌル キー]チェック ボックスがオンの場合にのみ使用できます。 | バイナリ ゼロ |
大小文字無視 | セグメントで大文字小文字が区別されるかどうかを設定します。この設定は、STRING、LSTRING、ZSTRING のデータ型、または ACS を使用しないキーに対してのみ有効です。 | オン |
降順ソート | キー セグメント値を降順(大きいものから小さいものへ)でソートするかどうかを指定します。 | オフ |
ACS を使用する | セグメントで、キーに定義されたオルタネート コレーティング シーケンスを使用するかどうかを設定します。この設定は、大文字小文字が区別される STRING、LSTRING、ZSTRING のデータ型に対してのみ使用できます。 | オフ |
ヌル値の離散順序 | ヌル値の離散順序は、ヌル インジケーター セグメント(NIS)で、MicroKernel エンジンが NIS を Boolean として扱って非ゼロ値をすべてヌルと見なすのか、1 バイトの Integer として扱ってゼロが非ヌルでその他すべての値を異なるタイプのヌルと見なすのかを決定するのに使用されます。この場合、これらは離散値としてソートされます。Btrieve API は NO_CASE フラグ 0x0400 がこれまで Integer 値に使用されていなかったので、これを使用し、離散順序ソートが実行されるようにします。 | オフ |
重複キーの操作方法
複数のレコードが、インデックス キーに同一の重複した値を持つことができます。重複キー値を持つレコードを記憶しておく 2 つの方法は、リンク重複および繰り返し重複と呼びます。
リンク重複
リンク重複の手法では連鎖技術を使用し、グループ内の各レコードをポインターを使用して隣のレコードと連結します。同一インデックス ページ上の各エントリは 1 組のレコード ポインターを持ち、キー値が重複しているレコードの連鎖の最初と最後のリンクを示します。このため、各キー ページのエントリは繰り返し重複インデックスより 4 バイト長くなります。さらに、データ ページの各レコードでは、リンク重複インデックスごとに 8 バイトのオーバーヘッドが必要です。この 8 バイトは、連鎖中の次のレコードと前のレコードを指す 2 つのレコード ポインターです。
最初のレコード ポインターは、最初に、または最も古い時期に格納されたレコードのアドレスを保持します。2 番目のポインターは最近または最後に格納されたレコードのアドレスを保持します。最初のレコードが書き込まれた後でほかのレコードが追加される前には、キー ページ エントリ上の両方のポインターに最初のレコードのアドレスが保持されています。その後にレコードが追加されると、2 番目のポインターが追加された各レコードを指すように変更されます。このことにより、最後のレコードのレコード ポインターが、レコードの追加時にデータ ページ内に構築される前のレコードの連鎖のリンクとして使用されること、および前のレコードの検索に使用されることが可能になります。
繰り返し重複
繰り返し重複の手法では、各重複キー値はインデックス ページとデータ ページ上のレコード内の両方に格納されます。各キー値には、レコード ポインターが 2 つではなく 1 つだけあります。この手法ではデータ レコードの連鎖が不要で、レコードごとの 8 バイトのオーバーヘッドを節約します。キー値が重複レコードごとに繰り返されるため、インデックスのサイズが大きくなるという影響があります。
手法の比較
リンク重複および繰り返し重複の手法は、以下の基準によって比較することができます。
•順序付け
•ストレージ
•パフォーマンス
•並行性
順序付け
リンク重複インデックスは、データが追加された順序で重複を取得します。繰り返し重複インデックスは、データがファイル内に存在する順序で重複を取得します。ファイル内での位置は制御できないため、順序はランダムであると考える必要があります。
ストレージ
リンク重複インデックスでは、各重複キー値の最初の出現で 12 バイト余分に必要になります。これには、各レコードについての 8 バイトとキー ページ エントリとしての 4 バイトが含まれます。ただし、重複レコードはキー ページでこれ以外の余計な空間を必要とせず、レコードごとに 8 バイトが追加されるだけです。したがって、キー値ごとの重複の数が増加してキー値のサイズが増加しても、リンク重複インデックスはキー ページが使用するストレージ空間を著しく節約することができます。ただし、重複キーを持つレコードがほとんどファイルに格納されていないか、キー長が非常に短い、またはその両方に該当する場合は、使用するストレージ空間は増加します。
次の図で、リンク重複インデックスの使用によって節約されるストレージ空間の量を例示します。リンク重複インデックスは、キー値ごとの重複レコード数が少ない場合にはより多くの空間を必要とするので注意してください。しかし、キー値ごとの重複レコード数が増えるにつれ、リンク重複インデックスが必要とするページ数は少なくなり、ストレージ空間を著しく節約します。
図 20 重複キー手法によるページ数の比較
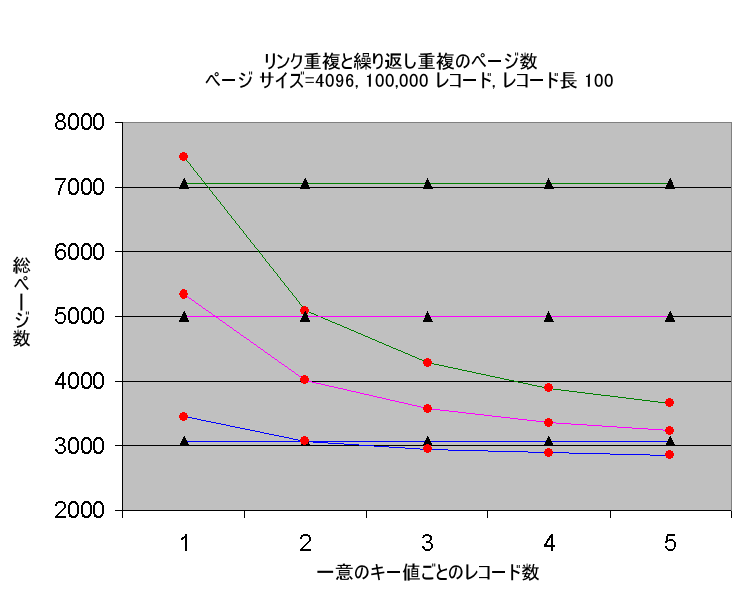
凡例: |  = リンク重複 |  = 繰り返し重複 |
| 先頭の 2 行はキー長 100 を表します
中央の 2 行はキー長 50 を表します
下部の 2 行はキー長 4 を表します |
パフォーマンス
インデックス検索に関わるページが少ない場合、ディスクから読み取るページ数が少なくなるため、結果として速いパフォーマンスが得られます。リンク重複手法は一般的に少しの物理ストレージ空間しか使用しないため、速いパフォーマンスが得られます。繰り返し重複手法は、重複のあるキー数が少ない場合にのみパフォーマンスでの利点があります。
並行性
データベース エンジンは、複数の並行トランザクションが同一ファイルに対し同時にアクティブである場合に、ページ レベルの並行性を提供します。これは、キー ページへのほとんどの変更と、データ ページへのすべての変更に適用されます。並行性とは、同一ページが別個のトランザクションからの複数の保留中の変更を同時に持つことができることを意味します。また、これらのトランザクションはどのような順序でもコミットすることができます。繰り返し重複インデックスはこの並行性を最もよく利用しています。
リンク重複インデックスでは、繰り返し重複には存在しない並行性の制限が追加されます。新しい重複データが作成された場合、そのレコードはリストの最後で別のレコードにリンクされます。このレコードのリンクにより、1 つではなく 2 つのレコードがロックされることになります。すべての重複データはリンク レコードの連鎖の最後に追加されるため、重複は一度に 1 つしか追加できません。
このようなレコード ロックの衝突により、通常、ほかのクライアントは最初のトランザクションがコミットされるまで待機状態になります。並行動作が行われる環境では、すべての新規レコードが同じ重複値を使用する場合、並行性は事実上一度に 1 トランザクションというレベルまで低減します。さらに、トランザクションが大きいかまたは長く継続する場合、この連続状態がパフォーマンスに非常に大きく影響します。
並行環境で更新されるデータベースに繰り返し重複インデックスを使用した場合、パフォーマンスは一般的に向上します。したがって、リンク重複手法を使用せざるを得ない理由がある場合を除き、並行環境で更新されるデータベースには繰り返し重複インデックスを使用してください。
情報エディターでの作業
ファイル情報エディターを使用して次の作業を行うことができます。
既存ファイルからの情報のロード
既存ファイルから情報をロードした場合、既存ファイルを編集するわけではありません。既存ファイルに関する情報のコピーのみがロードされます。一般的に、ファイル情報エディターでほかの作業をする前にファイルをロードしますが、これは必須ではありません。
►既存データ ファイルからファイル情報エディターに情報をロードするには
1 [ファイル情報エディター]ダイアログ ボックスの上部の[情報のロード]をクリックします。[ファイルの選択]ダイアログ ボックスが表示されます。
図 21 [ファイルの選択]ダイアログ ボックス
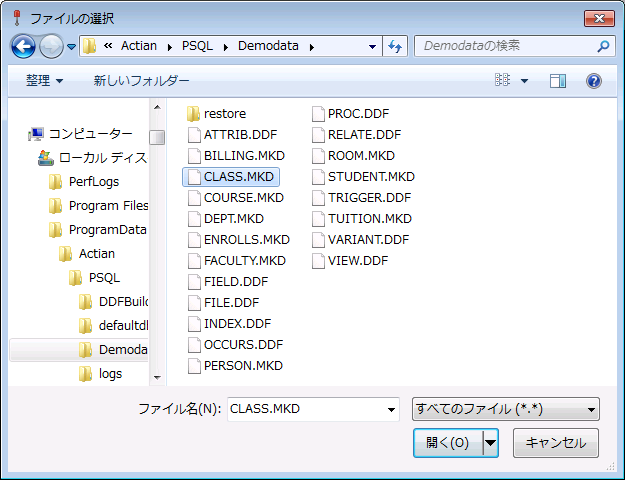
2 情報をロードするファイルの名前とパスを指定します。デフォルトでは、データ ファイルの拡張子は .mkd になっていますが、それ以外の拡張子、または拡張子なしも可能です。
Maintenance ツールでは、指定されたファイルを、まずデータ ファイルとして開こうとします。ファイルにオーナー ネームが必要な場合は、オーナー ネームを求めるメッセージが表示されます。指定されたファイルがデータ ファイルでない場合、このツールではそのファイルを、ディスクリプション ファイルとして開こうとします。
新規ファイルの作成
ファイル情報エディターで、現在の情報または入力した新しい情報に基づいた新規ファイルを作成することができます。
►ファイル情報エディターの現在の情報に基づいて新規ファイルを作成するには
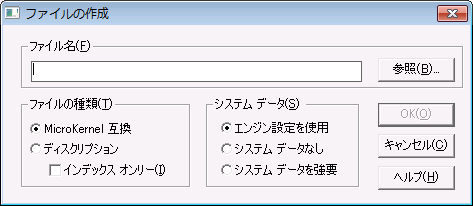
1 [ファイル情報エディター]ダイアログ ボックスの上部の[ファイルの作成]をクリックします。[ファイルの作成]ダイアログ ボックスが表示されます。
図 22 [ファイルの作成]ダイアログ ボックス
2 [
ファイルの作成]ダイアログ ボックスで設定を行います。各コントロールについては、表
71 を参照してください。
表 71 [ファイルの作成]ダイアログのコントロール
コントロール | 説明 | デフォルト |
|---|
ファイル名 | ファイルの名前とパスを指定します。デフォルトでは、データ ファイルの拡張子は .mkd になっています。 | 適用外 |
ファイルの種類 | 作成するファイルの種類を指定します。ディスクリプション ファイルを作成する場合は、[ インデックス オンリー]オプションを使用して、 butil ツールで既存データ ファイルへのインデックス追加に使用できるディスクリプション ファイルを作成できます(詳細については、 インデックスの作成を参照してください)。 | MicroKernel 互換 |
システム データ | ファイルにシステム データを含めるかどうかを設定します[ エンジン設定を使用]を選択した場合は、[ システム データ]設定オプションの設定が適用されます。[ システム データなし]を選択した場合、エンジンの設定にかかわらず、システム データは作成されません。[ システム データを強要]を選択した場合は、エンジンの設定にかかわらず、システム データが作成されます。 この設定は、ファイルの種類が[MicroKernel 互換]の場合にのみ有効になります。 | エンジン設定を使用 |
ディスクリプション ファイルへのコメントの追加
コメントは、ディスクリプション ファイルを作成したときに、その先頭に出力されます。たとえば、コメント「これは私のファイルです」はディスクリプション ファイルの先頭に /* これは私のファイルです*/ と表示されます。ディスクリプション ファイル作成後にコメントを追加する場合は、コメントを追加してファイルを作成し直す必要があります。
►ディスクリプション ファイルにコメントを追加するには
1 [ディスクリプション コメント]をクリックします。[ディスクリプション ファイル コメント]ダイアログ ボックスが表示されます。
2 全角で 2,560 文字(半角で 5120 文字)以内のコメントを入力します。
3 コメント入力後、[OK]をクリックします。
Btrieve データ ファイルのコンパクト化
未使用スペースを除去することにより Btrieve データ ファイルのコンパクト化を行うことができ、通常ファイルのサイズを小さくすることができます。この処理は、コマンド ライン Maintenance ツール(
Btrieve データ ファイルをコンパクト化するにはを参照)を使用して実行することもできます。
►Btrieve ファイルをコンパクト化するには
1 ファイル情報エディターの[情報のロード]をクリックし、コンパクト化するファイルを選択します。
2 [ファイルの作成]をクリックし、[ファイルの作成]ダイアログ ボックスに、複製する新しいファイルの名前を入力して[OK]をクリックします。
3 メイン ウィンドウの[データ]メニューから[保存]をクリックします。[データの保存]ダイアログ ボックスの[保存元 MicroKernel ファイル]ボックスに元のファイルの名前を入力し、[保存先シーケンシャル ファイル]ボックスに出力ファイルの名前(たとえば <元のファイル名>.out)を入力します。
4 [実行]をクリックします。[データの保存]ダイアログ ボックスに、保存の結果が表示されます。[閉じる]をクリックします。
5 [
データ]メニューの[
ロード]をクリックします。[
データのロード]ダイアログ ボックスの[
ロード元シーケンシャル ファイル]ボックスに、保存したシーケンシャル データ ファイルの名前を入力します。ステップ
2 で作成した複製ファイルの名前を[
ロード先 MicroKernel ファイル]ボックスに入力します。
6 [実行]をクリックします。[データのロード]ダイアログ ボックスに、ロードの結果が表示されます。[閉じる]をクリックします。
元のファイルと複製されたファイルのサイズを比較すると、コンパクト化の結果を確認できます。
キーのオルタネート コレーティング シーケンスの指定
オルタネート コレーティング シーケンス(ACS)を使用して、文字型のキー(STRING、LSTRING および ZSTRING)を標準 ASCII コレーティング シーケンスとは異なる順序でソートすることができます。1 つまたは複数の照合順序を使用して、次のようにキーをソートすることができます。
•英数字(A-Z および 0-9)と非英数字(# など)の混在した独自のユーザー定義ソート順による
•マルチ バイト コレーティング要素、符号、および文字の拡張と短縮を含む言語固有のコレーションに適合する、インターナショナル ソート規則(ISR)による
ファイルには、キーごとに異なる ACS を持つことができますが、1 つのキーには 1 つの ACS のみです。したがって、キーがセグメント化されている場合、各セグメントはそのキーに指定された ACS を使用するか、または ACS をまったく使用しないかのいずれかになります。あるファイルに、一部のセグメントにだけ ACS が指定されているキーがある場合、Btrieve は指定されたセグメントのみ、ACS を使用してソートします。
ISR テーブルは ISO の標準ロケール テーブルに基づいており、Zen によって提供されます。ISR テーブルは Zen のデータベース エンジンと一緒にインストールされた collate.cfg ファイルに格納されています。複数のデータ ファイルが 1 つの ISR を共有できます。
►キーのオルタネート コレーティング シーケンスを指定するには
1 [ACS 情報]をクリックします。
Maintenance ツールに[ACS 情報の指定]ダイアログ ボックスが表示されます。
図 23 [ACS 情報の指定]ダイアログ ボックス
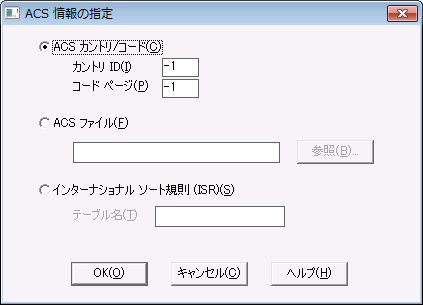
2 ACS ファイル名またはインターナショナル ソート規則(ISR)のいずれかを、以下のように指定できます。
表 72 ACS 情報のコントロール
コントロール | 説明 | デフォルト |
|---|
ACS カントリ/コード | 使用されなくなりました。 | 適用外 |
ACS ファイル | オルタネート コレーティング シーケンス ファイルのフル パス名を指定します。 | 適用外 |
インターナショナル ソート規則 | 国際データをソートするために使用する、ISR テーブルを選択することができます。Zen には、『Zen Programmer's Guide』に一覧表示された ISR テーブルがあらかじめ用意されています。 | |
3 データ ファイルに ACS ファイル名を指定した場合は、ACS ファイルの内容がデータ ファイルにコピーされます(データ ファイルには、ACS ファイルの名前は含まれません)。ACS は、8 バイトの名前(UPPER など)で識別され、Maintenance ツールでは、データ ファイルの ACS 情報に、元の ACS のファイル名ではなく、この 8 バイトの名前が表示されます。
4 ディスクリプション ファイルに ACS ファイルを指定した場合は、ACS ファイルの実際のパスとファイル名がディスクリプション ファイルにコピーされます。その結果、ディスクリプション ファイルの ACS 情報を表示する場合、Maintenance ツールは指定した ACS ファイルを検索しようとします。
ISO で定義されている言語固有のコレーティング シーケンスを使用して文字列の値をソートする ACS を指定する場合は、ISR テーブル名を指定します。[テーブル名]フィールドへの入力は、半角で 16 文字までです。ISR の詳細については、開発者リファレンスの『Zen Programmer's Guide』を参照してください。
オーナー ネームの管理
MicroKernel は、個々のデータ ファイルにそれぞれオーナー ネームを設定することにより、データ ファイルへのアクセスを個別に制限することができます。オーナー ネームを提供するユーザーのみが、ファイルに対する読み取り/書き込みが可能となります。このトピックでは、Maintenance ツールを使用したオーナー ネームの管理について説明します。詳細については、
オーナー ネームを参照してください。
オーナー ネームによる制限があるテーブルへリレーショナル アクセスしようとしたときに、そのオーナー ネームの文字列値を提供しないと ODBC エラーになります。たとえば、これは ZenCC でテーブルを削除しようとする場合などです。GRANT または SET OWNER ステートメントを使用すれば、セッション内で 1 つまたは複数のテーブルにオーナーネームを指定することができます。特定のユーザーまたはグループにアクセス権を付与して、ODBC 経由でテーブルをリレーショナル操作するには、GRANT ステートメントを使用します。Master ユーザーは GRANT ステートメントに正しいオーナー ネームを使用する必要があります。詳細については、『
SQL Engine Reference』の
GRANT を参照してください。
SET OWNER ステートメントを使用して、現在のデータベース セッション中にファイル アクセスを可能にするオーナー ネームを 1 つまたは複数提供します。詳細については、『
SQL Engine Reference』の
SET OWNER を参照してください。
オーナー ネームを設定またはクリアする
オーナー ネームを設定すると、データ ファイルへのアクセスが制限されます。オーナー ネームをクリアすると、この制限が解除されます。
►オーナー ネームを設定またはクリアするには
1 Maintenance ツール ウィンドウで、[オプション]>[オーナー ネームの設定/クリア]を選択して、[オーナー ネームの設定/クリア]ダイアログを開きます。
図 24 [オーナー ネームの設定/クリア]ダイアログ
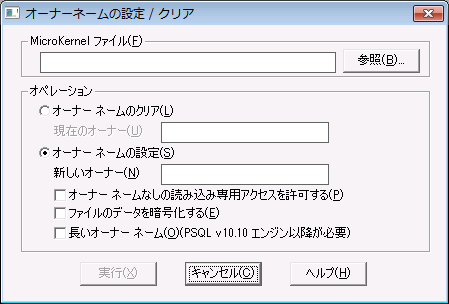
2 [MicroKernel ファイル]ボックスで、オーナー ネームを設定またはクリアするファイルを入力します。オーナー ネームをクリアする場合は、[オーナー ネームのクリア]をクリックし、[現在のオーナー]フィールドにファイルのオーナー ネームを入力してそのクリアを許可します。
3 オーナー ネームを設定する場合は、[オーナー ネームの設定]をクリックし、[新しいオーナー]フィールドに新しいオーナー ネームを入力して、その後、希望するオプションを選択します。
•[オーナー ネームなしの読み込み専用アクセスを許可する]をオンにすると、すべてのユーザーが、データ ファイルへの読み取り専用アクセスを許可されます。
•[ファイルのデータを暗号化する]をオンにすると、デバッガーやファイル ダンプ ツールを使用したデータへの不正アクセスを防ぐことができます。暗号化と復号により処理時間が増えるため、使用する環境でデータのセキュリティが優先される場合にのみ、このチェック ボックスをオンにしてください。
•[
長いオーナー ネーム]を選択して、8 バイト長の短いオーナー ネームよりも長いオーナー ネームを作成します。長いオーナー ネームの長さは、ファイル形式によって異なります。詳細については、
オーナー ネームを参照してください。
4 [実行]をクリックしてオプションを適用します。
メモ:オーナー ネームを指定するには GRANT ステートメントを使用することもできます。『
SQL Engine Reference』の
オーナー ネームによるアクセス権の付与を参照してください。
情報レポート
ファイル情報レポートの作成は、データベース エンジンのトランザクション一貫性保持機能でファイルのログを作成できるかどうかを確認する際に便利です。レポートは、ファイルにシステム データがあるかどうか、キーがユニークであるかどうかを表示します(ユニーク キーには、重複が許可されていることを示す D フラグが付きません)。情報レポートはファイルのメタデータを提供します。この情報は、問題の解決に使用したり、よく似たファイルを作成するのに役立ちます。
情報レポートの作業
情報レポートを作成する手順を以下に示します。
►既存データ ファイルのファイル情報レポートを作成するには
1 メイン ウィンドウのメニューで、[オプション]>[情報レポートの作成]をクリックします。Maintenance ツールに[ファイル情報レポート]ダイアログ ボックスが表示されます。
図 25 [ファイル情報レポート]ダイアログ ボックス
2 使用するデータ ファイルとレポートのファイル名を指定します。作成後にレポートを表示する場合は、[レポートを表示する]チェック ボックスをオンにします。
レポートを表示する設定にした場合、次のような[ファイルの表示]ウィンドウが表示されます。
図 26 ファイル情報レポートの例

ファイル情報レポートの情報ヘッダーは、
ファイル情報エディターに記述されているファイル情報エディターのコントロールに対応しています。
ファイル情報レポート下部の凡例には、レポートのキー/セグメントの部分で使用されている記号の説明が表示されます。この情報には、キーやキー セグメントの数、ファイル中のキーの位置、キー長などが含まれます。
凡例:
< = Descending Order
D = Duplicates Allowed
I = Case Insensitive
M = Modifiable
R = Repeat Duplicate
A = Any Segment (Manual)
L = All Segments (Null)
* = The values in this column are hexadecimal.
?? = Unknown
-- = Not Specified
インデックス
インデックスは、特定キーのすべてのキー値をソートするためのものです。Btrieve アクセスではオーバーラップするインデックス(列の一部を含むインデックス)が許可されます。ODBC を介したリレーショナル アクセスでは、オーバーラップするインデックスは許可されません。[エディターの起動]ボタンをクリックして表示できるファイル情報エディターを使用して、オーバーラップするインデックスを作成することができます。
インデックスの作業
インデックスに関連する以下の作業を行います。
インデックスの作成
ファイルにキーが定義されていない場合、ファイルのインデックスを作成することはできません。ファイル情報エディター(
ファイル情報エディターを参照)を使用してキーを作成することができます。
►インデックスを作成するには
1 メイン メニューで、[インデックス]>[作成]をクリックすると、[インデックスの作成]ダイアログ ボックスが開きます。
図 27 [インデックスの作成]ダイアログ ボックス
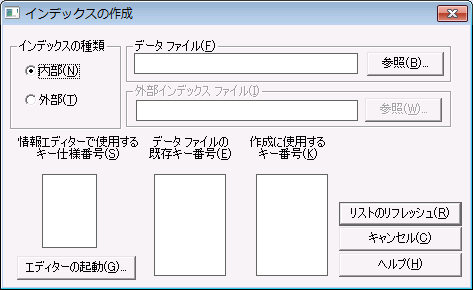
2 [インデックスの作成]ダイアログ ボックスで以下のオプション設定を行います。
インデックスの種類 | 内部インデックスと外部インデックスのどちらを作成するかを指定します。内部インデックスは、データ ファイルの一部として動的に管理されます。外部インデックスは、必要に応じて作成する別のファイルとなります。
外部インデックス ファイルは、指定するキーでソートされたレコードを含む標準データ ファイルです。各レコードは、以下の項目から成ります。 •元のデータ ファイルにおけるレコードの物理位置を識別する 4 バイト アドレス •キー値 |
データ ファイル | インデックスを作成するデータ ファイルの名前を指定します。 |
外部インデックス ファイル | 外部インデックスに作成するファイルの名前を指定します。内部インデックスには使用できません。 |
情報エディターで使用するキー仕様番号 | ファイル情報エディターで定義されたキー番号が表示されます。 |
データ ファイルの既存キー番号 | [リストのリフレッシュ]をクリックすると、ファイルに定義されているキー番号が表示されます。ファイルにシステム定義のログ キーが含まれている場合は、このリストに SYSKEY が表示されます。 |
作成に使用するキー番号 | [リストのリフレッシュ]をクリックすると、ファイルに定義されていない、使用可能なキー番号が表示されます。インデックスの作成時に使用するキー番号を選択します。 ファイルにシステム定義のログ キー(システム データ)が含まれ、そのキーが削除されている場合は、リストに SYSKEY が表示されます。それを選択することにより、システム定義のログ キーを再びファイルへ追加することができます。 |
3 [エディターの起動]をクリックすると、[ファイル情報エディター]ダイアログ ボックスにキーの詳細情報が表示されます。[リストのリフレッシュ]をクリックして、データ ファイルからキー情報を読み取ると、[データ ファイルの既存キー番号]リストと[作成に使用するキー番号]リストをリフレッシュできます。インデックスを作成する前に[リストのリフレッシュ]をクリックしてください。
4 [インデックスの作成]ダイアログ ボックスの設定完了後、[実行]をクリックしてインデックスを作成します。インデックス作成の所要時間は、ファイルに含まれるデータの量によって異なります。
インデックスの削除
インデックスを削除する前に、アプリケーション プログラムが行うアクセスについてよく理解しておいてください。必要なインデックスがないと、GET NEXT などの機能が動作しません。その結果、アプリケーション プログラムは正常に機能しなくなります。
►インデックスを削除するには
1 メイン メニューで、[インデックス]>[削除]をクリックします。[インデックスの削除]ダイアログ ボックスが表示されます。
図 28 [インデックスの削除]ダイアログ ボックス
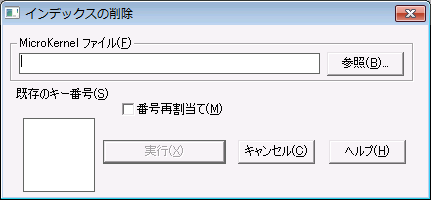
2 [インデックスの削除]ダイアログ ボックスで以下のオプション設定を行います。
MicroKernel ファイル | インデックスを削除するデータ ファイルの名前を指定します。 |
既存のキー番号 | [リストのリフレッシュ]をクリックすると、ファイルに定義されているキー番号が表示されます。削除するインデックスのキー番号を選択します。ファイルにシステム定義のログ キーが含まれている場合は、リストに SYSKEY が表示され、それを選択することにより、システム定義のログ キーをファイルから削除することができます。 |
番号再割当て | キーの番号を再割り当てします。このチェック ボックスをオンにすると、インデックス削除によって生じたキー番号の欠番がなくなります。 |
3 [リストのリフレッシュ]をクリックし、指定したファイルからキー情報を取得します。
データ
[データ]メニューのコマンドを使用して、データ ファイルのレコードをインポート、エクスポート、およびコピーすることができます。また、ロール フォワード機能を利用して、システム エラー発生後にデータを修復することも可能です。ロール フォワードについては、
ロール フォワード コマンドを参照してください。
ASCII ファイル形式のインポートとエクスポート
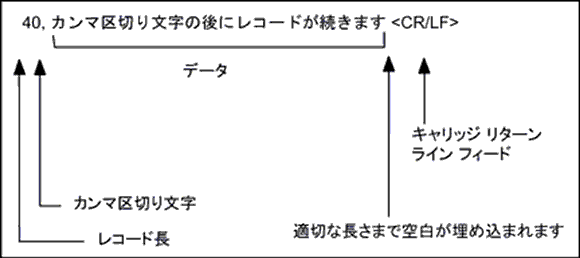
データを保存すると、ASCII ファイルのレコードは、以下の形式になります。以下の仕様に従うことにより、ASCII テキスト エディターを使用してロード可能なファイルを作成できます。多くのテキスト エディターでは、バイナリ データを編集することができないので注意してください。
•最初のフィールドは、レコードの長さを指定する左揃えの整数(ASCII 形式)です(この値の計算時、行末のキャリッジ リターン/ライン フィードは無視します)。このフィールドの値は、データ ファイルで指定されているレコード長と同じになります。
•固定長レコードを含むファイルでは、データ ファイルのレコード長と同じ長さを指定します。
•可変長レコードを含むファイルでは、データ ファイルの固定長レコード以上の長さを指定します。
•長さフィールドの次に、区切り文字(カンマまたはスペース)が入ります。
•区切り文字の次に、レコード データが続きます。データの長さは、長さフィールドで指定したバイト数とまったく同じにします。テキスト エディターを使用してインポート ASCII ファイルを作成する場合は、各レコードが適切な長さになるように、必要に応じてスペースで埋めてください。
•各行末には、キャリッジ リターン/ライン フィード(16 進数の 0D0A)を使用します。Maintenance ツールでは、データ ファイルにキャリッジ リターン/ライン フィードが挿入されません。
•ファイルの最終行には、ファイル終了文字(CTRL+Z または 16 進数の 1A)を使用します。多くのテキスト エディターでは、ファイルの最後にこの文字が自動的に挿入されます。
図
29 は、入力 ASCII ファイルのレコード形式です。この例では、データ ファイルに 40 バイトのレコード長が定義されています。
図 29 入力シーケンシャル ファイルのレコード形式
データに関する作業
以下のデータに関する作業は Maintenance ツールを使用して行うことができます。
•最後のバックアップからシステム エラーが発生する間に行った、データ ファイルへの変更の回復(ロール フォワード)の方法は、
ログ、バックアップおよび復元の章を参照してください。
ASCII ファイルからのレコードのインポート
Maintenance ツールでは、ASCII ファイルから標準データ ファイルにレコードをインポートすることができます。この処理では、データ変換は行われません。テキスト エディター、または Maintenance ツールを使用してインポート ファイルを作成することが可能です(
ASCII ファイルへのレコードのエスクポートを参照)。
►ASCII データをインポートするには
1 メイン メニューで[データ]>[ロード]をクリックします。[データのロード]ダイアログ ボックスが表示されます。
図 30 [データのロード]ダイアログ ボックス
指定する ASCII ファイルは、
ASCII ファイル形式のインポートとエクスポートで説明されている仕様に従っている必要があります。指定する標準データ ファイルのレコード長は、ASCII ファイル内のレコードと適合している必要があります。
2 [実行]をクリックしてレコードをインポートします。
データのインポート中は、インポートされたレコードの数とパーセンテージ、およびステータス メッセージが表示されます。このとき、Maintenance ツールでは別の作業(新しい[データのロード]ダイアログ ボックスを開くなど)を続けることもできます。
ASCII ファイルへのレコードのエスクポート
Maintenance ツールでは、データ ファイルから ASCII ファイルにレコードをエクスポートすることができます。
►ASCII レコードをエクスポートするには
1 メイン メニューで[データ]>[保存]をクリックします。[データの保存]ダイアログ ボックスが表示されます。
図 31 [データの保存]ダイアログ ボックス
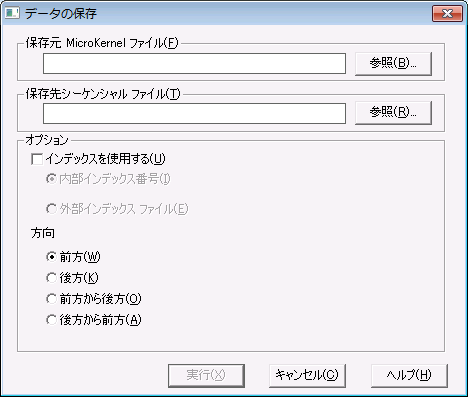
2 [データの保存]ダイアログ ボックスで、以下のオプションを設定します。
保存元 MicroKernel ファイル | 保存する既存 MicroKernel 互換ファイルの名前を指定します。 |
保存先シーケンシャル ファイル | 作成するシーケンシャル ファイルの名前を指定します。 |
インデックスを使用する | エクスポートするレコードをソートする際に、指定したインデックスを使用します。デフォルトでは、Maintenance ツールでインデックスは使用されず、レコードはデータ ファイル内の物理位置に従ってエクスポートされます。 |
| 内部インデックス番号:
指定したキー番号を使用します。[保存元 MicroKernel ファイル]ボックスのファイルを変更した場合は、[インデックス リストをリフレッシュ]をクリックして使用可能なインデックスを更新します。 |
| 外部インデックス ファイル:
指定した外部インデックスを使用します(外部インデックスの作成は、 インデックスの作成を参照)。 |
方向 | 前方:これがデフォルトの設定で、データ回復がファイルの先頭から末尾に向かって行われます。
後方:データ回復がファイルの末尾から行われます。
前方から後方:エラーが発生するまで、ファイルを前方から読み取ります。次に、エラーが発生したレコード、または別のエラーが発生したレコードまで、ファイルを末尾から読み取ります。
後方から前方:エラーが発生するまで、ファイルを後方から読み取ります。次に、エラーが発生したレコード、または別のエラーが発生したレコードまで、ファイルを先頭から読み取ります。 |
3 [
実行]をクリックしてデータをエクスポートします。Maintenance ツールによって、
ASCII ファイル形式のインポートとエクスポートの形式に従って、指定された ASCII ファイルが作成されます。その後、この ASCII ファイルを編集し、[
ロード]コマンドを使用して、編集したテキストを別の標準データ ファイルにインポートできます。
データ ファイル間のレコードのコピー
Maintenance ツールでは、MicroKernel データ ファイルから別の MicroKernel データ ファイルにデータをコピーすることができます。指定するデータ ファイルの両方のレコード長は、同じでなければなりません。
►MicroKernel データ ファイル間でレコードをコピーするには
1 メイン メニューで[データ]>[コピー]をクリックします。[データのコピー]ダイアログ ボックスが表示されます。
図 32 [データのコピー]ダイアログ ボックス
2 コピーするファイルの名前を[コピー元 MicroKernel ファイル]ボックスに入力し、ファイルのコピー先のパスを[コピー先 MicroKernel ファイル]ボックスに入力します。
指定するデータ ファイルの両方のレコード長は、同じでなければなりません。
データ ファイルへの変更の回復(ロール フォワード)
Btrieve の Maintenance コマンド ライン ツール(butil)
buti はコマンド ライン形式のインターフェイスを使用したい場合、または Continuous オペレーションを開始または停止したい場合に使用します。コマンド プロンプトで Maintenance コマンドを実行する、または、実行可能なバッチ スクリプトとして実行することができます。butil コマンドを実行する前に、ここで説明する当コマンドの概念や構文を理解してください。
Btrieve の Maintenance コマンド ライン ツールでは、以下のファイル処理およびデータ処理を行います。
リターン コード
butil は実行を完了すると、終了コードまたは DOS エラー レベルのリターン コードをオペレーティング システムに返します。リターン コードの種類は次の表に示すとおりです。
コード | 説明 |
|---|
SUCCESS_E = 0 | 要求された処理は正常に終了しました。 |
PARTIAL_E = 1 | 要求された処理は完了しましたがエラーが発生しました。 |
INCOMPLETE_E = 2 | 要求された処理は正常に終了しませんでした。 |
USAGE_E = 3 | 入力の構文エラー。使用方法を画面に表示し、終了します。 |
コマンド
次の表は、butil で使用できるコマンドの一覧です。表内のリンクから、詳細な情報へ移動できます。
コマンド | 説明 |
|---|
| ファイルのページをキャッシュへ事前ロードします。ただし、ファイルが完全にキャッシュされているか、またはキャッシュがいっぱいの場合にはロードされません(コマンド プロンプに戻ります)。Purge コマンドと対になるコマンドです。 |
| 既存のファイルの仕様を使い、空のデータ ファイルを新規作成します。 |
| データ ファイルのオーナー ネームをクリアします。 |
| データ ファイルの内容を、別のデータ ファイルにコピーします。 |
| データ ファイルを作成します。 |
| インデックスを削除します。 |
| バックアップを対象として定義されたファイルの Continuous オペレーションを停止します。 |
| 外部インデックス ファイルを作成します。 |
| データ ファイルにシーケンシャル ファイルの内容を読み込みます。 |
| ファイルの不要なキャッシュ ページをすべて消去します。ファイルがオープン ハンドルを持つ場合は消去されません(ただちにコマンド プロンプトに戻ります)。cache コマンドと対になるコマンドです。 |
| データ ファイルから連続的にデータを読み取り、シーケンシャル ファイルに結果を書き込みます。(ただし DOS バージョンでは、rollfwd は使用できません)。破損したファイルがある場合は、このコマンドを使用します。 |
Rollfwd | 最後のバックアップからシステム エラーが発生する間に行った、データ ファイルへの変更を回復します。 アーカイブ ロギングの実行を参照してください。 |
| キー パスのデータを読み取り、シーケンシャル ファイルに結果を書き込みます。 |
| データ ファイルにオーナー ネームを割り当てます。 |
| インデックスを作成します。 |
Startbu | バックアップを対象として定義されたファイルの Continuous オペレーションを開始します。 ログ、バックアップおよび復元を参照してください。 |
| ファイル属性の情報およびデータ ファイルの現在のサイズを表示します。 |
| MicroKernel エンジンとリクエスターをアンロードします。 |
| サーバーにロードされているデータベース エンジンおよびリクエスターのバージョンを表示します。 |
コマンド構文の表示
各コマンドの使用方法を表示するには、ファイル サーバー上のプロンプトで butil コマンドを入力します。
コマンド形式
butil の形式は以下のとおりです。
BUTIL [-command [parameter ...]] | @commandFile
–command | copy などの Maintenance ツールのコマンドが入ります。コマンドの前にはハイフン(-)を付け、ハイフンの前にはスペースを入力します。 |
parameter | コマンドに必要な情報です。詳細は各コマンドに応じて説明します。 |
@commandFile | コマンド ファイルのフル パス名 |
コマンド ファイル
コマンド ファイルは、以下の処理に使用します。
•コマンド ラインに収まらない、長いコマンドの実行
•頻繁に使用するコマンドの実行(コマンド ファイルに一度入力し、その後はそのコマンド ファイルを実行)
•以下のコマンド形式を使用した、コマンドの実行とその出力のファイルへの書き込み
butil @commandFile [commandOutputFile]
コマンドを実行すると、結果の出力ファイルには、実行したコマンドとその結果が表示されます。すべてのメッセージは、サーバーのコンソール画面にも表示されます。
•複数コマンドの連続実行
コマンド ファイルには、コマンド ラインで必要な情報と同じものが含まれます。
コマンド ファイルの規則
Maintenance ツールのコマンド ファイルを作成する際、以下の規則に従ってください。
•1 つのパラメーターを 2 行に分割しない。
•各コマンドは、<end> または [end] で終わる必要があります。複数のコマンドを実行する場合は、各コマンドが <end> で終わっている必要があります。<end> または [end] には、小文字を使用します。
コマンド ファイルの例
以下は、コマンド ファイルの例 copycrs.cmd です。このファイルでは、butil - clone コマンドを呼び出し、course.mkd ファイルを複製することによって newcrs.mkd ファイルを作成します。次に -create コマンドを呼び出し、newfiles.des ディスクリプション ファイルのディスクリプションを使用して newfile.dta ファイルを作成します。
-clone newcrs.mkd course.mkd <end>
-create newfile.dta newfiles.des <end>
以下のコマンドでは、copypats.cmd ファイルを使用して copypats.out ファイルに書き込みを行います。
butil @copypats.cmd copypats.out
ディスクリプション ファイル
ディスクリプション ファイルは、データ ファイルとインデックスの作成に使用するファイルのディスクリプションおよびキー仕様を含む、ASCII ファイルです。作成したファイルの情報を保存するための媒体としてディスクリプション ファイルを使用することもできます。ディスクリプション ファイル形式の詳細については、
ディスクリプション ファイルを参照してください。
拡張ファイルのサポート
データベース エンジンの データ ファイルは、オペレーティング システムのファイル サイズ上限を超えた容量を持つことが可能です。データを、MicroKernel の拡張ファイルからシーケンシャル ファイルにエクスポートした際、実際の形式の違いから、そのシーケンシャル ファイルの容量がデータベース エンジンのファイル サイズ上限を超える場合があります。
大きなサイズのファイルがエクスポートされる際、対話型 Maintenance ツールでは、シーケンシャル ファイルがオペレーティング システムのファイル サイズの上限(2 GB)を超えていることを検出すると、エクステンション ファイルの作成が開始されます。この処理は自動的に行われます。エクステンション ファイルおよび元のシーケンシャル ファイルは、同じボリューム内に存在する必要がありますエクステンション ファイルの名前には、ベース ファイルと似た名前を付ける方式が使用されます。エクステンション ファイルを示すのに、ネイティブな MicroKernel エンジン エクステンション ファイルがキャレット("^")を使用するのに対し、シーケンシャル ファイルのエクステンション ファイルはチルダ("~")を使用するので、同じベース ファイル名を持つ既存の MicroKernel エンジン拡張ファイルを上書きするのを防ぎます。最初のエクスポート エクステンション ファイルには、ベース ファイル名に ".~01" という拡張子が付きます。次のエクステンション ファイルには、ベース ファイル名に ".~02" というように拡張子が付けられます。これらの拡張子は 16 進形式で追加されます。
名前付け規則は 255 までのエクステンション ファイルをサポートしますが、現在のエクステンション ファイルの最大数は 64 です。したがって、最大ファイル サイズは 128 GB です。
シーケンシャル ファイルに対する、サイズの大きなファイルの
Save または
Recover については、それぞれのコマンドを参照してください。また、シーケンシャル ファイルからデータをインポートする場合は、そのファイルが拡張されているかどうかがチェックされ、エクステンション ファイルからデータがロードされます。
オーナー ネーム
MicroKernel を使用すると、ファイルのオーナー ネームを指定することにより、個々のファイルへのアクセスを制限することができます。オーナー ネーム文字列は暗号化にも使用されます。詳細については、
オーナー ネームを参照してください。
エラー メッセージのリダイレクト
エラー メッセージをリダイレクトする場合は、フル パス名(ドライブ文字または UNC パスを含む)を入力します。
►エラー メッセージをファイルへリダイレクトするには
•以下のコマンド形式を使用します。
BUTIL -command commandParameters > filePath
ASCII ファイル形式
「対話型 Maintenance ツール」セクションの、
ASCII ファイル形式のインポートとエクスポートを参照してください。
異なるプラットフォームでのファイル名指定の規則
Windows、Linux、または macOS で butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。
データのインポートとエクスポート
このトピックでは、
BUTIL コマンドの
Copy、
Load、
Recover、および
Save を使用したデータのインポートおよびエクスポートの詳細について説明します。
表 73 データのインポートとエクスポートを行うコマンド
コマンド | 説明 |
|---|
| データ ファイルの内容を、別のデータ ファイルにコピーします。 |
| データ ファイルにシーケンシャル ファイルの内容を読み込みます。 |
| データ ファイルからシーケンシャルにデータを読み取り、シーケンシャル ファイルに結果を書き込みます。 |
| キー パスのデータを読み取り、シーケンシャル ファイルに結果を書き込みます。 |
メモ:SQL ステートメントによって取得したデータをエクスポートする方法については、
deu を参照してください。
Copy
copy コマンドは、MicroKernel ファイルの内容を、別のファイルにコピーします。copy は、入力データ ファイルの各レコードを取得して、出力データ ファイルに挿入します。両ファイルのレコードのサイズは同じである必要があります。レコードのコピー後、copy によって新しいデータ ファイルに挿入されたレコードの総数が表示されます。
copy コマンドを使用することにより、古いファイルからのデータと新しいキー属性を持つデータ ファイルを作成できます。
►MicroKernel データ ファイルをコピーするには
1 Create コマンドを使用し、任意のキー属性(キー位置、キー長、重複キー値)を持つ空のデータ ファイルを作成します。
または
Clone コマンドを使用して、既存ファイルの属性を使った空のデータ ファイルを作成します。
2 copy コマンドを使用し、既存データ ファイルの内容を、新しく作成したデータ ファイルにコピーします。
形式
butil -copy sourceFile outputFile [/O<owner1 | /PROMPT>
[/O<owner2 | /PROMPT>]] [/UIDuname /PWDpword [/DBdbname]]
sourceFile | レコードをコピーする元となるデータ ファイルのフル パス名。Windows プラットフォームで butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
outputFile | レコードを挿入する先のデータ ファイルのフル パス名。出力データ ファイルにはデータが入っていても空でもかまいません。Windows プラットフォームで butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
/Oowner1 | ソース データ ファイルのオーナー ネーム(必要な場合)。出力データ ファイルのみでオーナー ネームが必要な場合は、/O に続けて owner1 にスペースを指定します(使用例を参照してください)。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。 |
/Oowner2 | 出力データ ファイルのオーナー ネーム(必要な場合)。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。 |
/UID<name> /UIDuname | セキュリティが設定されているデータベースにアクセスする権限を与えられたユーザー名を指定します。 |
/PWD<word> /PWDpword | uname で識別されるユーザーのパスワードを指定します。uname が指定された場合、pword は必ず指定する必要があります。 |
/DB<name> /DBdbname | セキュリティが設定されたデータベース名を指定します。省略した場合はデフォルトのデータベースと解釈されます。 |
例
以下のコマンドは、course.mkd のレコードを newcrs.mkd にコピーします。course.mkd 入力ファイルに、オーナー ネームは必要ありませんが、newcrs.mkd 出力ファイルでは、オーナー ネーム Pam が使用されています。
butil -copy course.mkd newcrs.mkd /O /OPam
この例から最初の /O を省略した場合、オーナー ネーム Pam は、出力データ ファイルではなく、入力データ ファイルのものとして認識されます。
ファイルをコピーするときに、元のファイルとコピーされるファイルの両方のオーナーネームが必要な場合、-copy オプションでは次の例に示すように、両方のオーナーネームを指定します。
butil -copy originalFile copiedFile /Od3ltagamm@ /OV3rs10nXIII
最初のオーナーネーム d3ltagamm@ は originalFile を開くために必要です。2 番目のオーナーネーム V3rs10nXIII は copiedFile の作成に使用します。
オーナーネームが対話形式で指定される場合、このコマンドは次に示す例のようになります。
butil -copy originalFile copiedFile /PROMPT /PROMPT
これを実行すると、最初にユーザーは originalFile にアクセスするためのオーナーネームの入力を求められます。そのファイルが開いたら、次に copiedFile に割り当てるオーナーネームの入力が求められます。
Load
load コマンドは、入力 ASCII ファイルのレコードをファイルに挿入します。入力 ASCII ファイルは、1 つのファイルまたは拡張ファイル(ベース ファイルと複数のエクステンション ファイル)のどちらでもかまいません。load コマンドでは、入力 ASCII ファイルのデータは変換されません。データ ファイルへのレコード移動後、ロードされたレコードの総数が表示されます。
メモ:load コマンドは、アクセラレイティド モードで出力ファイルを開きます。ロード オペレーション中は、ファイルのログは作成されません。アーカイブ ログを使用している場合は、load コマンド使用後にデータ ファイルを再度バックアップします。
拡張ファイル:次のエクステンション ファイルが検出された場合は、ロードが継続されます。save コマンドおよび recover コマンドで作成してあるエクステンション ファイルは、削除しないでください。ファイルに 3 つのエクステンション ファイルが存在し、ユーザーが 2 つ目のエクステンション ファイルを削除した場合は、1 つ目のエクステンション ファイル処理後に、レコードのロードが中止されます。
save または recover コマンドにより作成されたエクステンション ファイルは 3 つなのに、4 つ目のエクステンション ファイルが以前の save または recover コマンドで作成されて存在している場合、4 つ目のエクステンション ファイルからもレコードが読み取られ、データベース エンジン ファイルに挿入されます。4 つ目のエクステンション ファイルが存在する場合は、load 処理の開始前に削除してください。
load コマンド実行前には、入力 ASCII ファイルおよびデータ ファイルを作成する必要があります。入力 ASCII ファイルは、標準のテキスト エディターやアプリケーションを使用して作成できますが、そのファイル形式(
ASCII ファイル形式のインポートとエクスポートを参照)に従う必要があります。データ ファイルは、
Create コマンドまたは
Clone コマンドを使用して作成できます。
形式
butil -load unformattedFile outputFile [/O<owner> | /PROMPT] [/UIDuname /PWDpword [/DBdbname]]
unformattedFile | データ ファイルにロードするレコードを含む ASCII ファイルのフル パス名。Windows プラットフォームでは、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
outputFile | レコードを挿入する先のデータ ファイルのフル パス名。Windows プラットフォームで butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
/Oowner | データ ファイルのオーナー ネーム(必要な場合)。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。 |
/UID<name> /UIDuname | セキュリティが設定されているデータベースにアクセスする権限を与えられたユーザー名を指定します。 |
/PWD<word> /PWDpword | uname で識別されるユーザーのパスワードを指定します。uname が指定された場合、pword は必ず指定する必要があります。 |
/DB<name> /DBdbname | セキュリティが設定されたデータベース名を指定します。省略した場合はデフォルトのデータベースと解釈されます。 |
例
以下の例では、シーケンシャル レコードを course.txt から course.mkd に読み込みます。course.mkd のオーナー ネームは Sandy です。
butil -load course.txt course.mkd /OSandy
Recover
recover コマンドは、MicroKernel ファイルからデータを取り出し、
Load コマンドで使用する入力 ASCII ファイルと同じ形式の ASCII ファイルに書き込みます。これは、破損した MicroKernel ファイルから、一部または全部のデータを取り出すときに便利です。
recover コマンドは、すべてではないにしても、ファイルのレコードの多数を取り出すことができます。この後は、
load コマンドを使用し、新しい MicroKernel ファイルに回復したレコードを挿入します。
メモ:Maintenance ツールでは、レコードのデータは変換されないため、テキスト エディターを使用してバイナリ データを含む出力ファイルを編集する場合、テキスト エディターによってはバイナリ データが変更されてしまい、予期しない問題が発生する場合があります。
形式
BUTIL -RECOVER sourceFile unformattedFile [/O<owner> | /PROMPT] [/Q] [/J] [/I]
[/UIDuname /PWDpword [/DBdbname]]
sourceFile | 回復するデータを含むデータ ファイルのフル パス名。Windows プラットフォームで butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
unformattedFile | 回復したレコードを保存する ASCII ファイルのフル パス名。 |
/Oowner | データ ファイルのオーナー ネーム(必要な場合)。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。 |
/Q | 既存のシーケンシャル ファイルに上書きするかどうかを指定します。デフォルトでは、既存のファイルに上書きされます。このオプション使用時に同名のファイルが存在する場合は、エラー メッセージが表示されます。
また、回復の対象となるデータベース エンジン ファイルが拡張されているかどうかがチェックされます。ファイルが拡張されている場合は、存在する可能性のあるエクステンション ファイルと同名のファイルが存在するかどうかもチェックされます。このいずれかのファイルが存在する場合は、エラー メッセージが表示されます。 |
/J | ファイルを後方から読み取ります。このオプションを使用した場合は、step last と step previous オペレーションを使用してデータベース エンジン ファイルのデータ回復が行われます。デフォルトでは、step first と step next オペレーションを使用してファイルの先頭からデータが読み取られます。 |
/I | ファイルを前方から読み取ります。デフォルトでは、前方から読み取られますが、このオプションを使用して前方および後方を指定することができます。/I および /J の両方を指定した場合は、エラーが発生するまで前方からファイルが読み取られます。次に、発生したエラーまで、または別のエラーが発生するまで、ファイルを最後から読み取ります。
/J を最初に指定した場合は、まず後方から、次に前方から読み取ります。 |
/UID<name> /UIDuname | セキュリティが設定されているデータベースにアクセスする権限を与えられたユーザー名を指定します。 |
/PWD<word> /PWDpword | uname で識別されるユーザーのパスワードを指定します。uname が指定された場合、pword は必ず指定する必要があります。 |
/DB<name> /DBdbname | セキュリティが設定されたデータベース名を指定します。省略した場合はデフォルトのデータベースと解釈されます。 |
ソース ファイルの各レコードでは、recover コマンドで可変ページ エラー(ステータス コード 54)が発生した場合、現在のレコードから取得できるすべてのデータをシーケンシャル ファイルに書き込み、回復処理を継続します。
ツールでは、以下のメッセージが表示されます。
•最後に作成されたエクステンション ファイルの名前に関する情報が表示されます。
•次のエクステンション ファイルの存在をチェックし、存在する場合、削除が指示されます。
•拡張シーケンシャル ファイルを移動した場合、ベース ファイルとその全エクステンション ファイルの移動が指示されます。
例
以下のステートメントでは、course.mkd からレコードを取り出し、course.txt に書き込みます。
butil -recover course.mkd course.txt
Save
save コマンドは、指定したインデックス パスを使用して MicroKernel ファイルからデータを読み込み、
load コマンドで使用する形式に対応した ASCII ファイルに書き込みます。その後、その ASCII ファイルを編集し、
load コマンドを使用して編集後のデータを、別のデータ ファイルに保存することができます。ASCII ファイル形式の詳細については、
ASCII ファイル形式のインポートとエクスポートを参照してください。
save は、入力データ ファイルの各レコードに対して、出力 ASCII ファイルにレコードを 1 つ作成します。完了後、save によって保存されたレコードの総数が表示されます。
メモ:Maintenance ツールでは、レコードのデータは変換されないため、テキスト エディターを使用してバイナリ データを含む出力ファイルを編集する場合、テキスト エディターによってはバイナリ データが変更されてしまい、予期しない問題が発生する場合があります。
形式
butil -save sourceFile unformattedFile [Y indexFile | N <keyNumber | -1>] [/O<owner1 | /PROMPT> [/O<owner2 | /PROMPT>]] [/Q] [/J] [/I] [/UIDuname /PWDpword [/DBdbname]]
sourceFile | 保存するレコードを含むデータ ファイルのフル パス名。Windows プラットフォームで butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
unformattedFile | レコードを保存する ASCII ファイルのフル パス名。 |
indexFile | デフォルトの設定である最小キー番号を使用してレコードを保存しない場合、レコードを保存する外部インデックス ファイルのフル パス名。 |
keyNumber | デフォルトの設定である最小キー番号を使用してレコードを保存しない場合、レコードを保存するキー番号(0 以外)。 |
-1 | Btrieve Step オペレーションを使用して、物理的順序に従ってレコードを保存する場合に指定します。 |
/Oowner1 | ソース ファイルのオーナー ネーム(必要な場合)。インデックス ファイルのみでオーナー ネームが必要な場合は、/O に続けて owner1 にスペースを指定します。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。 |
/Oowner2 | インデックス ファイルのオーナー ネーム(必要な場合)。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。 |
/Q | 既存のシーケンシャル ファイルに上書きするかどうかを指定します。デフォルトでは、既存のファイルに上書きされます。このオプション使用時に同名のファイルが存在する場合は、エラー メッセージが表示されます。
また、回復の対象となるデータベース エンジン ファイルが拡張されているかどうかがチェックされます。ファイルが拡張されている場合は、存在する可能性のあるエクステンション ファイルと同名のファイルが存在するかどうかもチェックされます。このいずれかのファイルが存在する場合は、エラー メッセージが表示されます。 |
/J | ファイルを後方から読み取ります。このオプションを使用した場合は、get last と get previous オペレーションを使用してデータベース エンジン ファイルのデータ回復が行われます。デフォルトでは、get first と get next オペレーションを使用してファイルの保存が行われます。 |
/I | ファイルを前方から読み取ります。デフォルトでは、前方から読み取られますが、このオプションを使用して前方および後方を指定することができます。/I および /J の両方を指定した場合は、エラーが発生するまで前方からファイルが読み取られます。次に、発生したエラーまで、または別のエラーが発生するまで、ファイルを最後から読み取ります。
/J を最初に指定した場合は、まず後方から、次に前方から読み取ります。 |
/UID<name> /UIDuname | セキュリティが設定されているデータベースにアクセスする権限を与えられたユーザー名を指定します。 |
/PWD<word> /PWDpword | uname で識別されるユーザーのパスワードを指定します。uname が指定された場合、pword は必ず指定する必要があります。 |
/DB<name> /DBdbname | セキュリティが設定されたデータベース名を指定します。省略した場合はデフォルトのデータベースと解釈されます。 |
ツールでは、以下のメッセージが表示されます。
•最後に作成されたエクステンション ファイルの名前に関する情報が表示されます。
•次のエクステンション ファイルの存在をチェックし、存在する場合、削除が指示されます。
•拡張シーケンシャル ファイルを移動した場合、ベース ファイルとその全エクステンション ファイルの移動が指示されます。
例
以下の 2 つの例は、save コマンドを使用した、データ ファイルからのレコード取得方法です。
この例では、newcrs.idx 外部インデックス ファイルを使用して course.mkd からレコードを取得し、それらを course.txt という名前のシーケンシャル テキスト ファイルに保存します。
butil save course.mkd course.txt newcrs.idx
この例では、キー番号 3 を使用して course.mkd からレコードを取得し、それらを course.txt という名前のシーケンシャル テキスト ファイルに保存します。
butil -save course.mkd course.txt n 3
データ ファイルの作成と変更
このセクションでは、
Clone、
Clrowner、
Create、
Drop、
Index、
Setowner、および
Sindex といった各種 butil コマンドを使用した、データ ファイルの作成と変更に関する詳細について説明します。またこのセクションでは、
Btrieve データ ファイルのコンパクト化で、Btrieve データ ファイルの未使用スペース削除に関して詳細に説明します。
注意: 同じディレクトリに、ファイル名が同一で拡張子のみが異なるようなファイルを置かないでください。たとえば、同じディレクトリ内のデータ ファイルの 1 つに Invoice.btr、もう 1 つに Invoice.mkd という名前を付けてはいけません。このような制限が設けられているのは、データベース エンジンがさまざまな機能でファイル名のみを使用し、ファイルの拡張子を無視するためです。ファイルの識別にはファイル名のみが使用されるため、ファイルの拡張子だけが異なるファイルは、データベース エンジンでは同一のものであると認識されます。
表 74 データ ファイルの作成と変更を行うコマンド
コマンド | 説明 |
|---|
| 既存ファイルの仕様を使い、空の新規データ ファイルを作成します。 |
| データ ファイルのオーナー ネームをクリアします。 |
| データ ファイルを作成します。 |
| インデックスを削除します。 |
| 外部インデックス ファイルを作成します。 |
| データ ファイルにオーナー ネームを割り当てます。 |
| インデックスを作成します。 |
Clone
clone コマンドは、既存ファイルと同じファイル仕様(オーナー ネームを含まず、補足インデックスを含む)を持つ、空の新規ファイルを作成します。新しいデータ ファイルには、既存ファイルのすべての定義済みキー属性(キー位置、キー長、重複キー値など)が含まれます。
clone コマンドでは、ファイル情報(
システム データを参照)に影響する MicroKernel 設定オプションのすべてが無視されます(ファイル バージョンを
除く)。
clone コマンドは、[
作成ファイルのバージョン]オプションで指定したデータベース エンジンのファイル バージョンを使用して新規ファイルを作成します。
形式
BUTIL -CLONE outputFile sourceFile [/O<owner> | /PROMPT] [/pagecompresson | /pagecompressoff] [/recordcompresson | /recordcompressoff] [/UIDuname /PWDpword [/DBdbname]] [/S]
outputFile | 空の新規データ ファイルに使用するフル パス名。Windows プラットフォームで butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
sourceFile | 複製する既存データ ファイルのフル パス名。Windows プラットフォームで butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
/Oowner | ソース データ ファイルにオーナー ネームが割り当てられている場合は、そのオーナー ネーム。ソース ファイルのオーナー ネームは出力ファイルには複製されないので注意してください。その出力ファイルにオーナー ネームが必要な場合は、個別に追加しなければなりません。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。詳細については、 オーナー ネームを参照してください。 |
/pagecompresson | データベース エンジンのファイル互換性プロパティにある[作成ファイルのバージョン]が 9.5 または 13.0 の場合は、outputFile のページ圧縮をオンにします。 |
/pagecompressoff | outputFile のページ圧縮をオフにします。このパラメーターは、sourceFile にページ圧縮が使用されていない場合は無効です。 |
/recordcompresson | outputFile のページ圧縮をオンにします。 |
/recordcompressoff | outputFile のレコード圧縮をオフにします。このパラメーターは、sourceFile にレコード圧縮が指定されていない場合は無効です。 |
/UID<name> /UIDuname | セキュリティが設定されているデータベースにアクセスする権限を与えられたユーザー名を指定します。 |
/PWD<word> /PWDpword | uname で識別されるユーザーのパスワードを指定します。uname が指定された場合、pword は必ず指定する必要があります。 |
/DB<name> /DBdbname | セキュリティが設定されたデータベース名を指定します。省略した場合はデフォルトのデータベースと解釈されます。 |
備考
Btrieve 6.0 以降では、ページ サイズが 1024 バイトのデータ ファイルで最大 23 のキー セグメントを使用することができるため、
clone コマンドでは、既存データ ファイルに 24 のキー セグメントが含まれ、ページ サイズが 1024 バイトの場合、新規データ ファイルのページ サイズは 2048 バイトに設定されます。これは、既存データ ファイルがバージョン 6.0 より前の形式で、データベース エンジン ロードの際に、
作成ファイルのバージョン オプションが 5.
x または 6.
x に設定されていない場合に発生します。
バージョン 7.x 以前のファイルを複製する場合は、作成する新規ファイルのバージョン設定を確認してください。たとえば、6.15 ファイルを 9.5 形式で複製する場合は、データベース エンジンのファイル互換性プロパティで[作成ファイルのバージョン]オプションを 9.5 に設定します。
メモ:ソース ファイルが 8.x、9.5、または 13.0 形式でシステム データを含まない場合は、データベース エンジンの設定にかかわらず、出力ファイルにもシステム データは含まれません。既存ファイルへのシステム データの追加については、『Getting Started with Zen』を参照してください。
ステータス コード 30(指定されたファイルは MicroKernel ファイルではありません)が発生し、ソース ファイルのヘッダー ページが破損している可能性がある場合、ディスクリプション ファイルで
Create コマンドを使用して新規の MicroKernel ファイルを作成します。
例
以下のコマンドは、course.mkd ファイルを複製して newcrs.mkd ファイルを作成します。
butil -clone newcrs.mkd course.mkd
Clrowner
CLROWNER コマンドは、MicroKernel ファイルのオーナー ネームをクリアします。
形式
BUTIL -CLROWNER sourceFile </O<owner | /PROMPT> [/UIDuname /PWDpword [/DBdbname]]
sourceFile | データ ファイルの完全なフル パス名。Windows プラットフォームで butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
/Oowner | クリアするオーナー ネーム詳細については、 オーナー ネームを参照してください。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。 |
/UID<name> /UIDuname | セキュリティが設定されているデータベースにアクセスする権限を与えられたユーザー名を指定します。 |
/PWD<word> /PWDpword | uname で識別されるユーザーのパスワードを指定します。uname が指定された場合、pword は必ず指定する必要があります。 |
/DB<name> /DBdbname | セキュリティが設定されたデータベース名を指定します。省略した場合はデフォルトのデータベースと解釈されます。 |
例
以下のコマンドは、tuition.mkd のオーナー ネームをクリアします。オーナー ネームは Sandy です。
butil -clrowner tuition.mkd /OSandy
Create
create コマンドは、ディスクリプション ファイルで指定されている属性を使用して、空の MicroKernel ファイルを作成します。
create コマンドを実行する前に、新しいキー属性を指定するディスクリプション ファイルを作成します。詳細については、
ディスクリプション ファイルを参照してください。
形式
BUTIL -CREATE outputFile descriptionFile [< Y | N >] [/UIDuname /PWDpword [/DBdbname]]
outputFile | 作成するデータベース エンジン ファイルのフル パス名。ファイル名が既存の MicroKernel ファイルと同名の場合、既存ファイルの代わりに空の新規ファイルが作成されます。既存ファイルに保存されているデータは消去され、回復することができません。Windows プラットフォームで butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
descriptionFile | 新規 MicroKernel ファイルの仕様を含むディスクリプション ファイルのフル パス名。 |
Y | N | 既存のファイルに上書きするかどうかを指定します。このオプションに N を指定し、同名の MicroKernel ファイルが存在する場合は、エラー メッセージが表示されます。デフォルト設定は、Y です。 |
/UID<name> /UIDuname | セキュリティが設定されているデータベースにアクセスする権限を与えられたユーザー名を指定します。 |
/PWD<word> /PWDpword | uname で識別されるユーザーのパスワードを指定します。uname が指定された場合、pword は必ず指定する必要があります。 |
/DB<name> /DBdbname | セキュリティが設定されたデータベース名を指定します。省略した場合はデフォルトのデータベースと解釈されます。 |
例
以下のコマンドは、create.des ディスクリプション ファイルで定義された内容を使用し、ファイル course.mkd を作成します。
butil -create course.mkd create.des
create コマンドで使用するディスクリプション ファイルの例
図
33 の例では、MicroKernel 形式のファイルが作成されます。ファイルのページ サイズは 512 バイト、キーは 2 つに設定されています。ファイルの各レコードの固定長部は 98 バイト に設定されています。このファイルでは、可変長レコードがブランク トランケーション、レコード圧縮、可変長部割り当てテーブル(VAT)を使用しないように指定されています。空きスペース スレッショルドは、20 パーセントに設定されています。プリアロケーションは、100 ページに設定されています。ファイル作成時に、100 ページつまり 51,200 バイトがプリアロケートされます。
図 33 create コマンドで使用するディスクリプション ファイルの例

キー 0 は、重複可能で変更不可能な文字列セグメントを 2 つ含むセグメント キーで、この 2 つのセグメントには、16 進数で 20(スペース)のヌル値が指定されています。キー 0 では、コレーティング シーケンス upper.alt が使用されます。
キー 1 は、重複不可能で変更可能な数値型のセグメント化されていないキーです。これは、降順でソートされます。
Drop
drop コマンドは、ファイルからインデックスを削除し、それ以降のキー番号から 1 を引くことによって、残りのインデックスのキー番号を調整します。キーの番号を調整しない場合は、削除に指定したキー番号に 128 を加算します。この調整は、6.0 以降のファイルでのみ使用可能です。
形式
BUTIL -DROP sourceFile <keyNumber | SYSKEY> [/O<owner> | /PROMPT]
[/UIDuname /PWDpword [/DBdbname]]
sourceFile | インデックスを削除するファイルのフル パス名。Windows プラットフォームで butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
keyNumber | 削除するキー番号。元のキー番号を維持する場合は、指定したキー番号に 128 というバイアス値を足します。 |
SYSKEY | システム定義のログ キー(システム データ)を削除します。システム定義のログ キーを削除した場合でも、レコードから値は消去されず、新しく挿入されたレコードには、重複しないシステム定義のログ キー値が割り当てられます。 |
| しかし、重複しないユーザー定義のキーが存在しない限り、システム定義のログ キーが削除されたファイルのログは実行されません。この理由から、システム定義のログ キーが破損している可能性があり、再追加する場合にのみ、このオプションを使用してください。
SINDEX コマンドを使用すると、削除したシステム定義のログ キーを再利用できます。 |
/Oowner | ファイルのオーナー ネーム(必要な場合)。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。詳細については、 オーナー ネームを参照してください。 |
/UID<name> /UIDuname | セキュリティが設定されているデータベースにアクセスする権限を与えられたユーザー名を指定します。 |
/PWD<word> /PWDpword | uname で識別されるユーザーのパスワードを指定します。uname が指定された場合、pword は必ず指定する必要があります。 |
/DB<name> /DBdbname | セキュリティが設定されたデータベース名を指定します。省略した場合はデフォルトのデータベースと解釈されます。 |
例
以下の例では、course.mkd に 3 つのキーが存在します。ファイルの元のキーは、それぞれの番号が 0、1、2 となっています。
最初の例では、butil -drop コマンドで、course.mkd からキー番号 1 を削除し、残りのキー番号をそれぞれ 0 と 1 に調整します。
butil -drop course.mkd 1
以下の例では、butil –drop コマンドでキー番号 1 を削除し、キー番号の調整は行いません。キー番号は、それぞれ 0 と 2 のままになります。
butil -drop course.mkd 129
Index
index コマンドは、既存ファイルでキーとして指定されていないフィールドに基づき、既存 MicroKernel ファイルの外部インデックス ファイルを構築します。
index コマンドを実行する前に、新しいキー属性を指定するディスクリプション ファイルを作成します。ディスクリプション ファイルの詳細については、
ディスクリプション ファイルを参照してください。
新規ファイルのレコードは、以下から構成されます。
•既存データ ファイルに含まれる各レコードの 4 バイトのアドレス
•ソートの基準として使用する新しいキー値
メモ:ディスクリプション ファイルで指定したキー長が 10 バイトの場合、外部インデックス ファイルのレコード長は 14 バイト(10 + 4 バイト アドレス)になります。
形式
BUTIL -INDEX sourceFile indexFile descriptionFile [/O<owner> | /PROMPT]
[/UIDuname /PWDpword [/DBdbname]]
sourceFile | 外部インデックスを構築する既存ファイルの完全なフル パス名。Windows プラットフォームで butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
indexFile | 外部インデックスを保存するインデックス ファイルのフル パス名。 |
descriptionFile | 新しいキー定義を含む、作成したディスクリプション ファイルのフル パス。ディスクリプション ファイルには、新しいキーの各セグメントに対する定義が含まれている必要があります。 |
/Oowner | データ ファイルのオーナー ネーム(必要な場合)。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。詳細については、 オーナー ネームを参照してください。 |
/UID<name> /UIDuname | セキュリティが設定されているデータベースにアクセスする権限を与えられたユーザー名を指定します。 |
/PWD<word> /PWDpword | uname で識別されるユーザーのパスワードを指定します。uname が指定された場合、pword は必ず指定する必要があります。 |
/DB<name> /DBdbname | セキュリティが設定されたデータベース名を指定します。省略した場合はデフォルトのデータベースと解釈されます。 |
備考
index コマンドは、外部インデックス ファイルを作成し、インデックスが設定されたレコードの数を表示します。外部インデックス ファイルを使用して、データ ファイルのレコードを読み込む場合は、
Save コマンドを使用します。
index コマンドで使用するディスクリプション ファイルの例
以下のディスクリプション ファイルでは、1 つのセグメントを含む新しいキーを定義します。キーは、レコードの 30 バイト目から始まり、10 バイトの長さを持ちます。また、重複と変更が可能な STRING 型で、オルタネート コレーティング シーケンスを使用しません。
図 34 INDEX コマンドで使用するディスクリプション ファイルの例

例
以下のコマンドは、データ ファイル course.mkd を使用し、外部インデックス ファイル newcrs.idx を作成します。course.mkd ファイルには、オーナー ネームは必要ありません。新しいキーの定義を含むディスクリプション ファイルは、newcrs.des という名前です。
butil -index course.mkd newcrs.idx newcrs.des
Setowner
setowner コマンドは、データ ファイルのオーナー ネームを設定します。詳細については、
オーナー ネームを参照してください。
形式
BUTIL -SETOWNER sourceFile /O<owner | /PROMPT> level [/L] [/UIDuname /PWDpword [/DBdbname]]
sourceFile | データ ファイルのフル パス名。Windows プラットフォームで butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
/Oowner | 設定するオーナー ネーム。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。 |
level | データ ファイルのアクセス制限の種類。以下は、このパラメーターの説明です。 level は /O パラメーターの直後に置く必要があります。 |
| 0:すべてのアクセス モードでオーナー ネームが必要(データ暗号化なし) |
| 1:リード オンリー アクセスにはオーナー ネームは必要なし(データ暗号化なし) |
| 2:すべてのアクセス モードでオーナー ネームが必要(データ暗号化あり) |
| 3:リード オンリー アクセスにはオーナー ネームは必要なし(データ暗号化あり) |
/L | 長いオーナー ネームを指定します。 オーナー ネームでは大文字と小文字が区別されます。また、短いものと長いものがあります。短いオーナー ネームは半角 8 文字までの範囲で指定できます。長いオーナー ネームの長さは、ファイル形式によって異なります。詳細については、 オーナー ネームを参照してください。長いオーナー ネームに関する制限事項については、『 Btrieve API Guide』の Set Owner(29) の 手順トピックを参照してください。 |
/UID<name> /UIDuname | セキュリティが設定されているデータベースにアクセスする権限を与えられたユーザー名を指定します。 |
/PWD<word> /PWDpword | uname で識別されるユーザーのパスワードを指定します。uname が指定された場合、pword は必ず指定する必要があります。 |
/DB<name> /DBdbname | セキュリティが設定されたデータベース名を指定します。省略した場合はデフォルトのデータベースと解釈されます。 |
例
以下の例では、course.mkd データ ファイルの短いネームのオーナーを作成します。オーナー ネーム Sandy に制限レベル 1 を設定します。
butil -setowner course.mkd /OSandy 1
以下の例では、billing.mkd データ ファイル用の長いオーナー ネームを作成し、そのオーナー ネームとファイルを暗号化し、すべてのアクセス モードを制限します。
butil -setowner billing.mkd /Ohr#Admin$945k7YY%svr 2 /L
Sindex
sindex コマンドは、既存 MicroKernel ファイルに追加インデックスを作成します。デフォルトでは、新規インデックスのキー番号は、データ ファイルでそれまで最大だったキー番号より 1 つ大きな番号になりますが、キー番号を指定することも可能です。例外として、drop コマンドでインデックスを削除し、残りキー番号の調整を行わなかった場合は、未使用のキー番号が存在するため、新しいインデックスに最初の未使用番号が割り当てられます。
キー番号オプションを使用することにより、新規インデックスのキー番号を指定できます。指定するキー番号は、ファイルで使用されていない有効なキー番号でなければなりません。無効なキー番号を指定した場合は、ステータス コード 6 が返されます。
このコマンドで
SYSKEY オプションを使用しない場合は、
sindex コマンドを使用する前に、インデックスのキー仕様を定義するディスクリプション ファイルを作成する必要があります。ディスクリプション ファイルの詳細については、
ディスクリプション ファイルを参照してください。
形式
BUTIL -SINDEX sourceFile <descriptionFile | SYSKEY> [keyNumber] [/O<owner> | /PROMPT]
[/UIDuname /PWDpword [/DBdbname]]
sourceFile | 外部インデックスを構築する既存ファイルの完全なフル パス名。Windows プラットフォームで butil を使用する際、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
descriptionFile | 新しいキー定義を含む、作成したディスクリプション ファイルのフル パス。ディスクリプション ファイルには、新しいキーの各セグメントに対する定義が含まれている必要があります。 |
SYSKEY | システム キーが削除されたファイルに、システム キーを戻します。 |
/Oowner | データ ファイルのオーナー ネーム(必要な場合)。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。詳細については、 オーナー ネームを参照してください。 |
/UID<name> /UIDuname | セキュリティが設定されているデータベースにアクセスする権限を与えられたユーザー名を指定します。 |
/PWD<word> /PWDpword | uname で識別されるユーザーのパスワードを指定します。uname が指定された場合、pword は必ず指定する必要があります。 |
/DB<name> /DBdbname | セキュリティが設定されたデータベース名を指定します。省略した場合はデフォルトのデータベースと解釈されます。 |
例
以下の例では、course.mkd にインデックスを追加します。ディスクリプション ファイルの名前は、newidx.des です。
butil -sindex course.mkd newidx.des
以下の例では、システム定義キーが削除された course.mkd にシステム定義キーを追加します。
butil -sindex course.mkd syskey
Btrieve データ ファイルのコンパクト化
butil では、複数のコマンド(
Clone、
Recover、
Load)を使用してデータ ファイルの未使用スペースを削除し、ファイル サイズを縮小することができます。
►Btrieve データ ファイルをコンパクト化するには
1 データ ファイルの名前を変更し、
Clone オプションを使用して元のファイルと同名の空のデータ ファイルを作成します。
2 Recover を使用し、複製したファイルのデータを、シーケンシャル テキスト ファイルに保存します。
3 Load を使用し、回復されたデータを複製ファイルにロードします。
空のレコード以外のデータを含むすべてのレコードは、新しく作成したデータ ファイルにロードされます。この処理は、対話型 Maintenance ツールを使用して実行することもできます。
ファイルのページ キャッシュの管理
パフォーマンスを向上させるために、butil で cache コマンドと purge コマンドを使用してファイルのページ キャッシュを管理することができます。
注記
butil -cache および butil -purge コマンドがクライアント キャッシュ エンジンやレポート エンジンから実行される場合、そのコマンド アクションが適用されるのはローカル キャッシュにあるファイルのみです。
ファイルがクライアント キャッシュに残るようにするには、以下のいずれかの状況になっていなければなりません。
•ファイルが閉じている間にそのファイルに書き込みを行うマシンがほかにない
•最低 1 つのアプリケーションがクライアント マシンでファイルを開いておく必要がある
クライアント キャッシュ エンジンがアプリケーションとしてインストールされている場合は、シャットダウンしてクライアントがすべてのファイルを閉じた直後にキャッシュを空にします。これは、サービスとしてインストールされているクライアント キャッシュ エンジンやレポート エンジンの場合には問題になりません。
Cache
cache コマンドは、ファイルのページをキャッシュへ事前ロードします。ただし、ファイルが完全にキャッシュされているか、またはキャッシュがいっぱいの場合にはロードされません(コマンド プロンプに戻ります)。
形式
BUTIL -cache <sourceFile | @listFile>
sourceFile | キャッシュに事前ロードするデータ ファイルのフル パス名。Windows プラットフォームでは、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
@listFile | キャッシュに事前ロードするファイルのフル パス名を含む、テキスト ファイルのフル パス名。これらのパスは新しい行で区切り、各パスを個別の行に置きます。Maintenance ツールでエラーが発生した場合、ツールは応答しなくなります。 |
Purge
purge コマンドは、ファイルの不要なキャッシュ ページをすべて消去します。ファイルがオープン ハンドルを持つ場合は消去されません(ただちにコマンド プロンプトに戻ります)。
形式
BUTIL -purge <sourceFile | @listFile>
sourceFile | キャッシュから消去するデータ ファイルのフル パス名。Windows プラットフォームでは、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
@listFile | キャッシュから消去するファイルのフル パス名を含む、テキスト ファイルのフル パス名。これらのパスは新しい行で区切り、各パスを個別の行に置きます。Maintenance ツールでエラーが発生した場合、ツールは応答しなくなります。 |
データ ファイル情報の表示
このトピックでは、stat を使用してデータ ファイルの特性や統計情報に関するレポートを生成する方法を説明します。
Stat
stat コマンドは、定義されているデータ ファイルの特性、およびファイルの内容に関する情報を含むレポートを作成します。このコマンドを使用し、データベース エンジンがトランザクション一貫性保持機能を使ってファイルの情報を記録できるかどうかを判断できます。stat コマンドでは、Create Supplemental Index オペレーション(Btrieve 6.0 以降)および Create オペレーションのいずれで作成されたかに関わらず、同じインデックスが表示されます。
形式
BUTIL -STAT <sourceFile> [/O<owner> | /PROMPT] [/UIDuname /PWDpword [/DBdbname]]
sourceFile | 情報を表示するデータ ファイルのフル パス名。Windows プラットフォームでは、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
/Oowner | データ ファイルのオーナー ネーム(必要な場合)。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。詳細については、 オーナー ネームを参照してください。 |
/PROMPT | ユーザーがオーナー ネームを入力するための対話型プロンプトが提示されることを示します。 |
/UID<name> /UIDuname | セキュリティが設定されているデータベースにアクセスする権限を与えられたユーザー名を指定します。 |
/PWD<word> /PWDpword | uname で識別されるユーザーのパスワードを指定します。uname が指定された場合、pword は必ず指定する必要があります。 |
/DB<name> /DBdbname | セキュリティが設定されたデータベース名を指定します。省略した場合はデフォルトのデータベースと解釈されます。 |
ファイル統計情報の例
次の例は patients.dta ファイルの情報を表示します。
butil -stat patients.dta
以下はこのコマンドの結果です。
**************************************************
File Statistics for patients.dta
File Version = 8.00
Owner Name Protection = None
Encryption Level = None
Page Size = 2048
Page Preallocation = No
Key Only = No
Extended = No
Total Number of Records = 16
Record Length = 104
Record Compression = No
Variable Records = No
Available Linked Duplicate Keys = 0
Balanced Key = No
Log Key = 1
System Data = No
Total Number of Keys = 3
Total Number of Segments = 4
Key Segment Position Length Type Flags Null Values* Unique ACS Values
0 1 21 20 String MD -- 16 0
0 2 7 12 String MD -- 16 0
1 1 1 6 String M -- 16 0
2 1 83 10 String MD -- 7 0
Alternate Collating Sequence (ACS) List:
0 UPPER
凡例:
< = Descending Order
D = Duplicates Allowed
I = Case Insensitive
M = Modifiable
R = Repeat Duplicate
A = Any Segment (Manual)
L = All Segments (Null)
* = The values in this column are hexadecimal.
?? = Unknown
-- = Not Specified
この例では、patients.dta のファイル バージョンが 8.0 であることを表しており、これがファイル形式を読むことができる Btrieve の一番古いバージョンであることを示します。ファイルには、2048 バイトのページ サイズが指定されており、プリアロケート ページはありません。これは、キー オンリー ファイルでも拡張ファイルでもありません。
このファイルには 16 件のレコードが挿入されています。また、104 バイトのレコード長が定義されており、レコード圧縮は使用せず、可変長レコードも許可されていません。
このファイルには、利用可能なリンク重複キーはありません。インデックス バランスも使用しません。キー 1 を使用したログが実行され、ファイルには、システム定義のデータも存在しません。また、4 つのキー セグメントから構成される 3 つのキーが存在します。
メモ:Sindex で作成したインデックスには、「予約重複ポインター」要素を指定しない限り、デフォルトで R が割り当てられます。
統計情報レポートには、特定のキーに関する情報も表示されます。たとえば、キー 0 は2 つのセグメントから構成され、重複可能、変更可能であることがレポートに表示されます。このほか、以下も表示されます。
•最初のセグメントはポジション 21 から始まり、長さが 20 バイト、重複可能、変更可能、そして string 型として保存されます。ハイフンは、ヌル値が定義されていないことを表します。Unique Values の列は、16 個の重複しない値がセグメントに挿入されていることを表しています。このセグメントでは、オルタネート コレーティング シーケンス ファイル upper.alt が使用されます。
•2 つ目のセグメントはポジション 7 から始まり、長さが 12 バイト、重複可能、変更可能、そして string 型として保存されます。16 個の重複しない値が、このセグメントに挿入されています。このセグメントでは、オルタネート コレーティング シーケンス ファイル upper.alt が使用されます。
キー 1 は、このファイルのログに使用されるキーです。これは 1 つのセグメントで構成されます。ポジション 1 から始まり、長さが 6 バイト、重複不可、変更可能、そして string 型として保存されます。16 個の重複しないキー値が、このキーに挿入されています。このキーでは、オルタネート コレーティング シーケンス ファイル upper.alt が使用されます。
キー 2 は、1 つのセグメントで構成されます。ポジション 83 から始まり、長さが 10 バイト、重複可能、変更可能、そして string 型として保存されます。7 個の重複しないキー値が、このキーに挿入されています。このキーでは、オルタネート コレーティング シーケンス ファイル upper.alt が使用されます。
ファイル バージョンに関する注意
ファイル形式のバージョンを求められたら、データベース エンジンは指定したファイルを読むことのできる最も古いエンジンのバージョンを指定します。たとえば、5.x 形式で作成されたファイルがある場合でも、4.x または 5.x の機能を使用していないのであれば、レポートにはバージョン 3.x ファイルとして出力されます。6.x 形式で始めるには、ファイル自体にバージョン スタンプを含める必要があります。6.x より前のバージョンの場合、ファイル形式のバージョンを調べる唯一の方法は、ファイルで使用されている機能を調べることでした。これは、ファイル バージョンごとに利用できる機能に違いがあり、新しいファイル バージョンにはそれ以前のバージョンでは利用できない機能があるからです。
バージョン 5.x およびそれ以前のファイルについては、使用されている機能と、それによって特定できるファイル形式のバージョンを次の表に示します。
出力されるファイル バージョン | 以下の機能の 1 つ以上が使用されている場合 |
|---|
5.x | 圧縮レコード
キー オンリー ファイル |
4.x | 拡張キー タイプ
可変長レコード
Create Index オペレーションで追加されたインデックス |
3.x | 上記のいずれも使用していない |
MicroKernel エンジンのバージョンの表示
このセクションでは、ver コマンドを使用した、MicroKernel エンジンのバージョンの表示に関して説明します。
Ver
ver コマンドは、MicroKernel エンジンおよびリクエスター(アクセス モジュール)の両方のバージョン番号を表示します。
形式
butil -ver
備考
ver コマンドを実行した場合、以下のようなメッセージが表示されます。
Btrieve リクエスターのバージョンは 14.00 です。
Btrieve のバージョンは 14.00 で、xxx 版です。
MicroKernel エンジンとリクエスターのアンロード(DOS のみ)
Stop
stop コマンドは、MicroKernel エンジンおよびリクエスターをアンロードします。
形式
butil -stop
Continuous オペレーションの実行
Continuous オペレーションに関連するコマンド
startbu および
endbu については、
ログ、バックアップおよび復元で説明しています。
アーカイブ ロギングの実行
Maintenance ツール(GUI またはコマンド ラインの butil)は、アーカイブ ログ ファイルをデータ ファイルにロール フォワードする手段を提供します。
ログ、バックアップおよび復元も参照してください。
butil rollfwd コマンドは、最後のバックアップからシステム エラーが発生する間に行った、データ ファイルへの変更を回復します。システム エラーが発生した場合は、データ ファイルのバックアップ コピーを復元した後、butil rollfwd コマンドを使用し、ログに保存されているすべての変更を復元したデータ ファイルに適用します。バックアップからデータ ファイルを復元しない限り、このコマンドを使用しないでください。
メモ:rollfwd コマンドを利用するには、MicroKernel の[
選択ファイルのアーカイブ ロギング]オプションを
有効にし、システム エラー発生
前にファイルのバックアップを行う必要があります。
また、rollfwd コマンドを使用し、ログ オペレーションの出力ファイルを作成することも可能です。rollfwd コマンドでは、ロール フォワード前、またはロール フォワードと同時に出力ファイルを作成できます。
単一のファイルをロール フォワードすることもできますし、ボリューム上のすべてのデータ ファイル、ドライブ上のすべてのデータ ファイル、もしくは、ファイル、ボリュームおよび/またはドライブのリストをロール フォワードすることもできます。
GUI の使用
1 オペレーティング システムの[スタート]メニューまたはアプリ画面から、あるいは Zen Control Center の[ツール]メニューから Maintenance ユーティリティにアクセスします。
2 [Maintenance]ウィンドウで、[データ]>[ロール フォワード]を選択します。[ロール フォワード]ダイアログ ボックスが表示されます。
図 35 [ロール フォワード]ダイアログ
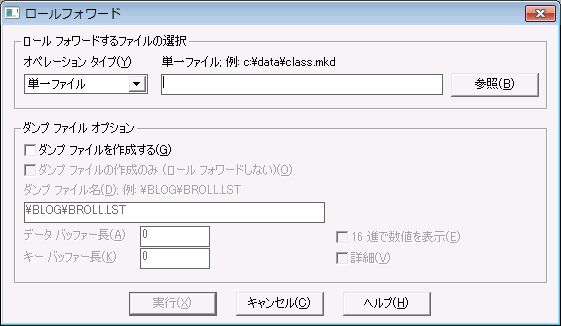
3 オペレーション タイプとして、"単一ファイル"、"ファイルのリスト"、"ボリューム名"、"ドライブ レター" のいずれかを選択します。"ボリューム名" または "ドライブ レター" を選択する場合は、名前の最後に円記号(\)またはスラッシュ(/)を挿入する必要があります(例、\\server\vol1\ または D:\ など)。
4 ロール フォワード タスクの実行に必要なすべての Btrieve オペレーションのリストである、ダンプ ファイルと呼ばれるログ ファイルを作成することができます。
デフォルトでは、このファイルは作成されません。ファイルを作成する場合は、[ダンプ ファイルを作成する]チェック ボックスをオンにします。以下のオプションも設定可能です。
表 75 ロール フォワード GUI オプション
ダンプ ファイルの作成のみ | ダンプ ファイルのみが作成され、ロール フォワードは実行されません。 |
ダンプ ファイル名 | これには、円記号(\)またはスラッシュで始まるダンプ ファイル名が含まれ、ドライブ文字、サーバー名またはボリューム名は含まれません。 |
データ バッファー長 | 各 Btrieve オペレーションで、ダンプ ファイルに書き込まれるデータ バッファーのバイト数を表します。 |
キー バッファー長 | 各 Btrieve オペレーションで、ダンプ ファイルに書き込まれるキー バッファーのバイト数を表します。 |
16 進で数値を表示 | このオプションを選択した場合は、ダンプ ファイル出力の数が 16 進形式で表示されます。このオプションを選択しない場合、数は十進形式で表示されます。 |
詳細 | ユーザー名、ネットワーク アドレス、タイムスタンプなど、ダンプ ファイルの補足情報が含まれます。 |
5 [実行]をクリックし、ダンプ ファイルの作成やロール フォワードを実行します。データが有効な場合は、[ロール フォーワード ステータス]ダイアログ ボックスが表示されます。
図 36 [ロール フォワード ステータス]ダイアログ ボックス
処理されたファイルは、リスト ボックスに追加され、ファイル名、およびロール フォワード オペレーションから返される Zen ステータス コードが表示されます。
処理中にエラーが発生した場合は、エラー時のロール フォワード続行を指定できるダイアログ ボックスが表示されます。このダイアログ ボックスでは、このダイアログを再表示することなく処理を継続するか、処理を継続して必要な場合にこのダイアログを再表示するか、またはファイル処理の中断を選択できます。
コマンド ラインの使用
このセクションでは、ロール フォワードをコマンド ラインで使用する構文を説明します。
BUTIL -ROLLFWD <sourceFile | drive | @listFile>
[</L[dumpFile] | /W[dumpFile]> [/T<dataLength>]
[/E<keyLength>] [/H] [/V] [/O<ownerList | owner> | /PROMPT]]
[/A] [/UID<name> <PWD<word>> [DB<name>]]
sourceFile | 変更をロール フォワードするデータ ファイルのフル パス名。Windows プラットフォームでは、データ ファイルが現在のディレクトリに存在する場合は、パスを指定する必要はありません。 |
drive | 変更をロール フォワードするドライブ文字。ボリューム名の最後には、円記号(\)またはスラッシュ(/)を使用します(例:F:\、F:/)。 |
@listFile | 変更をロール フォワードするファイルのパス、ボリューム、ドライブを含む、テキスト ファイルのフル パス名。これらのパスは、キャリッジ リターン/ライン フィードで区切ります。エラーが発生した場合は、現在のファイルのロール フォワードが中断されますが、その時点までの変更はロール バックされません。/A オプションを指定した場合は、次のファイルからロール フォワードが継続されます。 |
/LdumpFile | ロール フォワードを実行せず、出力ファイルを作成します。 |
/WdumpFile | ロール フォワードを実行し、出力ファイルを作成します。 |
dumpFile | ログ オペレーションが書き込まれる出力ファイルの名前。デフォルトは \blog\broll.lst で、物理ドライブのルートに関連付けられます。ファイル名は、スラッシュ(/)または円記号(\)で始まり、ドライブ文字やボリューム名は使用しません。ファイルは、blog.cfg と同じボリュームに配置されます。 |
/TdataLength | 出力ファイルに書き込む、オペレーションのデータ バッファーの長さを指定します。このオプションを指定しない場合は、出力ファイルにデータ バッファーの内容が含まれません。 |
/EkeyLength | 出力ファイルに書き込む、オペレーションのキー バッファの長さを指定します。このオプションを指定しない場合は、出力ファイルにキー バッファーの内容が含まれません。 |
/H | 出力ファイルの数値表示を 16 進数形式にします。このオプションを指定しない場合、出力ファイルの数値は ASCII 形式で表示されます。このオプションは、エントリ数、オペレーション コード、キー番号、データ長の各フィールドの形式に影響します。 |
/V | 出力ファイルに、補足情報(ユーザー名、ネットワーク アドレス、タイム スタンプなど)が追加されます。 |
/O | データ ファイルのオーナー ネームを指定します(必要な場合)。ログに記録したオペレーションの出力ファイルをリクエストし、データ ファイルのバックアップ コピーにリード オンリー アクセス用のオーナー ネームが存在する場合に、オーナー ネームが必要になります。/PROMPT オプションを使用すると、実行時にオーナー ネームの対話型プロンプトが生成されます。 2 つ以上のファイルにオーナー ネームがある場合は、それぞれのオーナー ネームはカンマで区切る必要があります。詳細については、 オーナー ネームを参照してください。 |
/A | 複数ファイルのロール バック中にエラーが発生した場合、次のファイルからロール フォワードを継続します。 このオプションを指定しない場合は、エラー発生時にロール フォワードが中断されます。その時点までの変更はロール バックされません。 メモ:/A オプションを使用した場合は、出力をファイルにリダイレクトできます。 エラー メッセージのリダイレクトおよび コマンド ファイルの説明を参照してください。 |
/UID<name> /UIDuname | セキュリティが設定されているデータベースにアクセスする権限を与えられたユーザー名を指定します。 |
/PWD<word> /PWDpword | uname で識別されるユーザーのパスワードを指定します。uname が指定された場合、pword は必ず指定する必要があります。 |
/DB<name> /DBdbname | セキュリティが設定されたデータベース名を指定します。省略した場合はデフォルトのデータベースと解釈されます。 |
メモ:実行する Btrieve オペレーションに対して、キー バッファーまたはデータ バッファーが入力パラメーターでない場合、ダンプ ファイルには何も書き込まれません。
例
例 A 次の例は、class.mkd ファイルに、デフォルトのアーカイブ ログおよびログ ロケーションから変更を回復します。
butil -rollfwd file_path\Zen\Demodata\class.mkd
ファイルのデフォルトの保存場所については、『
Getting Started with Zen』の
ファイルはどこにインストールされますか?を参照してください。
例 B この例では変更を回復し、それらを以下のオプションを使用して d:\ ボリュームのすべてのファイルに出力します。
•デフォルトのダンプ ファイル使用
•書き込むデータ バッファーの長さを 32 バイトに設定
•書き込むキー バッファーの長さを 4 バイトに設定
•16 進モードで書き込み
butil -rollfwd d:\/W /H /T32 /E4
例 C 以下の例では、ロール フォワードは実行されず、以下のダンプ オプションに従って、files.txt にリストされているファイルへの変更が出力されます。
•d:\temp\files.lst をダンプ ファイルとして使用
•詳細モードを使用
•データ ファイルにはオーナー ネーム own123 および own321 が含まれる
•データ バッファーやキー バッファーは出力しない
butil -rollfwd d:\temp\files.txt /L\temp\files.lst /V /Oown123,own321