
Araxis Mergeで活用できる正規表現

正規表現とは、文字列を表現する手法の一つです。例えば、ファイルを操作するときに文字列を「ワイルドカード」で表現する場合がありますが、正規表現を使用すると、より柔軟に文字列を扱うことができます。また、Linux では、sed, grep, vi など正規表現の理解を前提としたツールが多数用意されているので、効率的に作業を行うためにも正規表現の知識は身に付けておいた方がよいでしょう。
このようにプログラミングの世界では、一度覚えたら一生使えると言ってもいいほど利用価値が高い正規表現ですが、学習にはややハードルが高い面もあります。
これは、正規表現の書式が複雑になりがちなことに加え、作成した文字列パターンが正しく動作する定義なのか簡単に確認しづらいことが挙げられます。
Araxis Merge では、正規表現パターンを使ったマッチング条件を定義し、GUI を使ってリアルタイムで動作を確認できるため、間違いのないパターンを定義することができます。
このため、通常の Araxis Merge の使用方法とはやや異なりますが、正規表現をこれらから身に付けようとしている入門者が効果的に学習を進めるための「正規表現チェッカー」ツールとしても利用することが可能です。
今回は、Araxis Merge での正規表現の使用方法を説明します。
*目次*
1. 正規表現とは
正規表現は英語の「Regular Expression」を日本語に訳した用語で、略称として「RE」が使われる場合があります。
正規表現を使うと、Merge だけでなく、テキストエディタの検索や、プログラム言語での検索、抽出、置換処理で文字列を柔軟に取り扱うことができるようになります。
次のコマンドはファイルの一括削除でワイルドカードを使った事例です。
例)del *.txt
ワイルドカードでは、「*」は任意の文字列を意味しているので、この場合、ABC.txt でも XYZ.txt でも拡張子が「.txt」であれば削除を行うという意味になります。
ワイルドカードは扱いが簡単なため、単純な文字列検索などには大きな効果が得られますが、正規表現を使用すると、ワイルドカードでは対応できないような複雑なマッチングパターンを表現することが可能になります。
例えば、電話番号は基本的には数字で構成されますが、それぞれの桁数が微妙に異なる場合があります。また、市外局番がカッコで囲まれていたり、各番号がハイフンで区切られていたりする場合もあります。
03-5555-6666
(052)-777-8888
09099999999
このような、さまざまなフォーマットで電話番号が存在する場合、全てを正しい入力と判断する処理を新規で作成しようとすれば結構面倒なロジックが必要になります。
しかし、正規表現を使用すれば、これらの判定は 1 つのパターンを定義するだけで処理できます。
Merge がサポートしている書式については、次のオンラインマニュアルをご確認ください。
https://www.araxis.com/merge/documentation-windows/regular-expression-reference.ja
2. Merge での正規表現の登録
正規表現の書式を説明するとかなり多くの説明が必要になってしまうので、正規表現自体の説明は他のサイトに譲り、ここでは Merge での設定方法について解説します。
Linux のスクリプトなどでは、# で始まる文字列はコメントとして扱いますが、このコメントを Merge が無視するように設定してみましょう。
まず新規で正規表現を登録します。
[オプション]-[行の正規表現]-[行の正規表現の管理]
を選び、[新規(N)…]のボタンをクリックします。
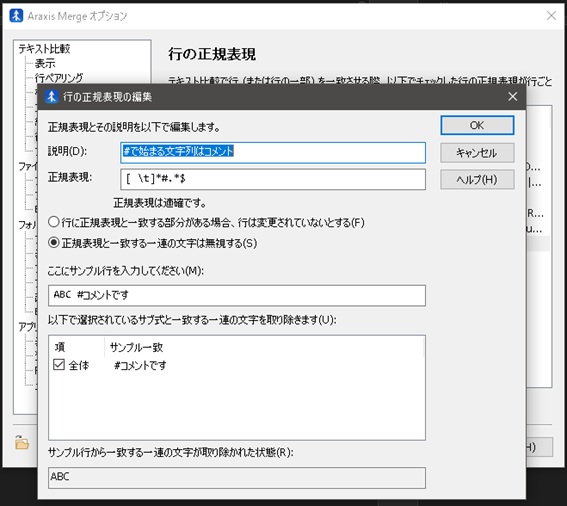
上記ダイアログが表示されるので、[正規表現]の欄に
[ \t]*#.*$
と入力してください。
また、その際、
[正規表現と一致する一連の文字列は無視する(S)]
を選択してください。
最初の [ \t] は半角スペースかタブのいずれかを意味しています。
続く * は直前の文字の 0 個以上の繰り返しを意味します。
つまり、[ \t]*# は空白文字(無くても良い)と、続く # 記号を表しています。
次の . は何らかの 1 文字を示す特殊記号です。
.* と続いていますので、該当の文字は無くても構いませんし、何文字か続いても構わないことを示しています。
最後の $ は行末を示す特殊記号です。
要約すると、「# で始まる文字列は、先頭の空白も含め、行末まで無視する」、と指定したことになります。
[ここにサンプルを入力してください(M):] の欄に
ABC #コメントです
と入力すると、コメント部が除去され ABC のみが残った状態になるのが視覚的に確認できます。
3. Merge での正規表現の利用
Merge には、正規表現を設定する2つのオプションがあります。
(1) 行に正規表現と一致する部分がある場合、行は変更されていないとする
例えば、新旧の PDF の比較の際に文章を追加した結果、ページ番号の場所がずれてしまい不一致として表示されてしまう、といった経験がある方は、このオプションでページ番号を無視することができます。
(2) 正規表現と一致する一連の文字は無視する
プログラムの途中に現れるコメント部の変更を無視して比較したい場合、このオプションで設定が可能です。
Merge を使った作業で、比較する必要がない部分が不一致と見なされると、本当に比較したい変更箇所が埋もれてしまい作業効率が落ちてしまう場合があります。 そのような状況でお困りの場合は、ここで説明した正規表現の活用をご検討ください。